広報・マーケティング担当者にとって、日々のニュース収集・分析は欠かせない業務です。
自社の露出状況を把握し、競合動向や市場トレンドをつかむことで、先手を打った広報施策・マーケティング戦略を打ち立てることができます。
しかし膨大な情報が日々発信される中で、必要な記事を効率的かつ的確に収集し分析するのは容易ではありません。
そこで注目されているのが、生成AIを活用したニュースの取得・分析です。生成AIは大量の情報源から自動で関連情報を集約・要約し、要点を整理することが可能なため、従来手間のかかっていたリサーチ作業が劇的に短縮されます。
本記事では、生成AI時代のニュース収集術を軸に、広報担当者が意識すべきポイントや具体的なプロセスを解説します。
ニュースデータの扱い方
まずニュースデータはどのように扱えばよいのでしょうか。
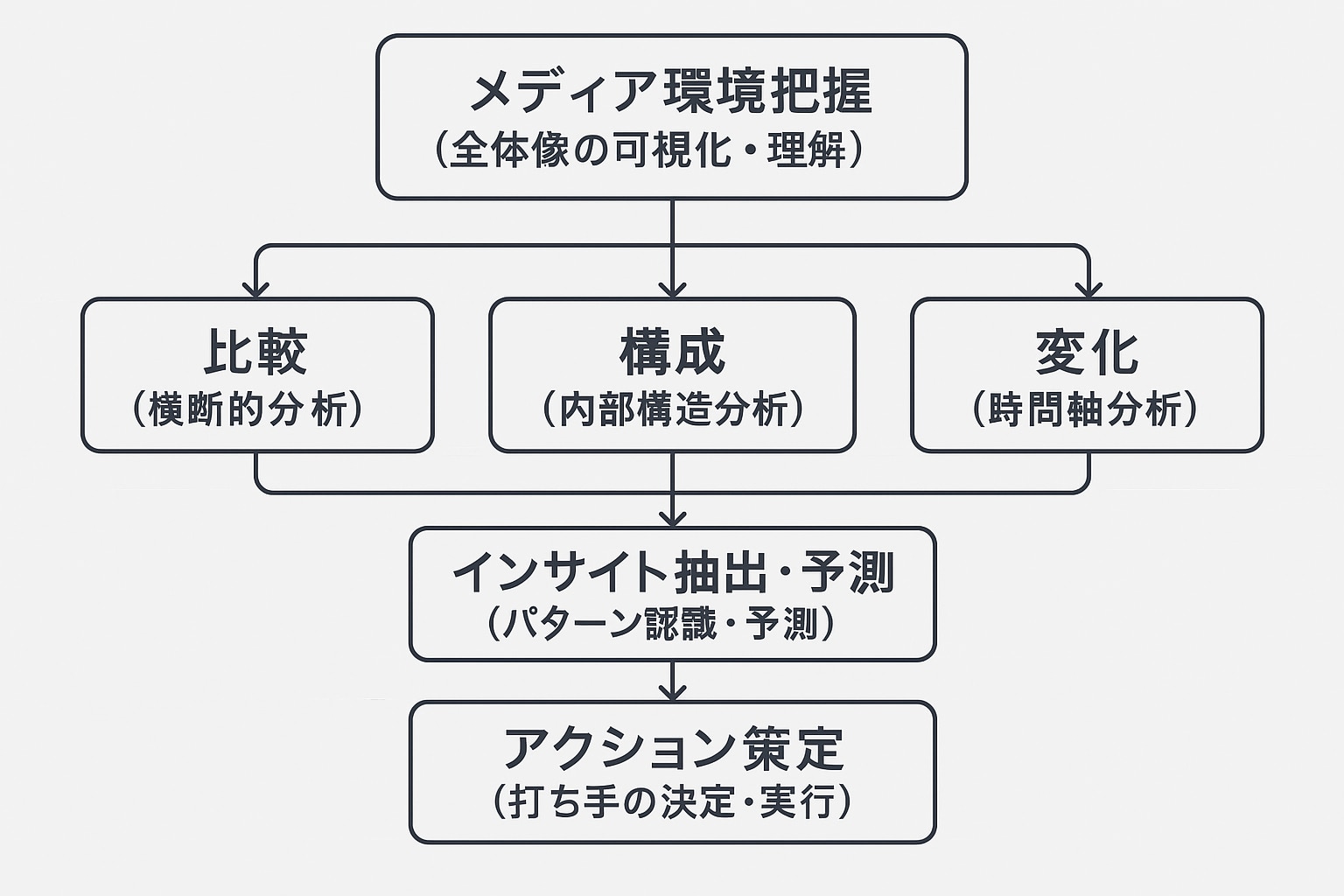
データの扱い方の基本は、名著『 イシューから始めよ』にも記載されている、以下の3つの軸を基本と考えるのが分かりやすいかと思います。

- 比較(データAとデータBを比較する)
自社と競合の記事数を比較する/リリースごとの露出数を比べる etc
- 構成(データの内訳比を見る)
どのメディアに取り上げられたか構成比を出す/ポジティブ・ネガティブなど感情割合を算出する etc
- 変化(時系列変化を見る)
昨年と今年の露出数変化を見る/増減タイミングを把握する etc
そしてこうした3軸をより分かりやすくするために、ダッシュボードなどの可視化が取り入れられます。
さらに既存データから未来予測をしたり、打ち手を考えたりすることも重要です。
この一連のタスクも生成AIが得意な分野と言えるでしょう。
ニュース取得をタスク分解
ニュースを分析するには、まずニュースを取得するプロセスが必要となります。
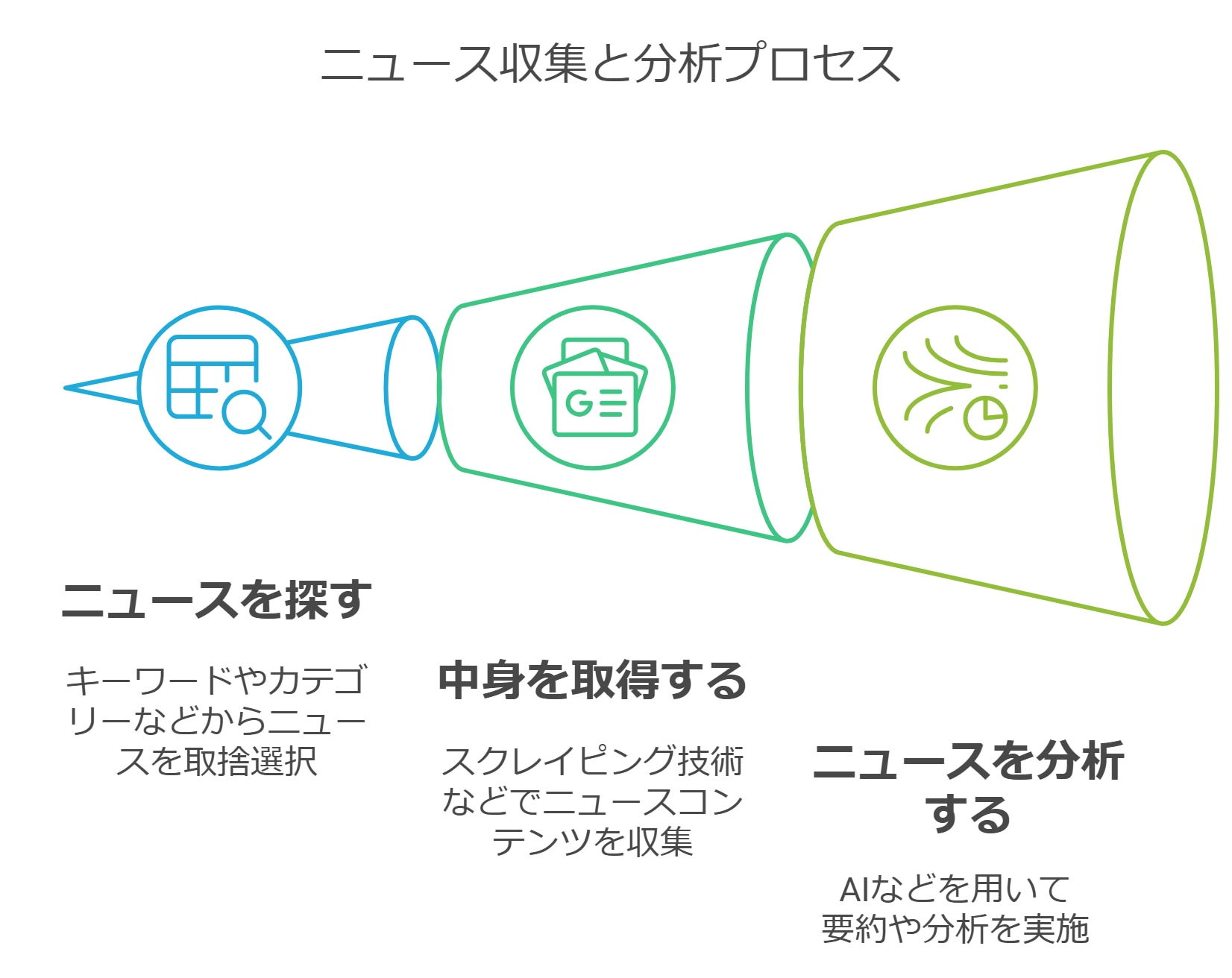
ニュース分析は、まずニュースを探し、中身を確認し、分析するという3つのプロセスに分けることができます。
ニュース処理の前提
そして この3つのプロセスを全て自動化することが今回の目的 となります。
自動化には、前提として以下の2つのポイントが重要となります。
1.プログラミングは必須(だがAIに任せられる)
自動化するにあたり、プログラミング処理はマストとなります。しかしこのプログラミング処理自体もAIがやってくれる時代が到来しています。
ReplitやDevinといったAIツールを使えば、環境構築や必要ファイル自体を自分で実装し、テストしてくれることもできるようになっています。
これらはバイブ・コーディングと呼ばれ、これからのプログラミング手法の主流となるとも言われています。
2.日付処理はとても重要
ニュース分析において、日付処理は単なる付加情報ではなく、分析の根幹を支える要素です。なぜなら「いつ」という情報がないニュースは、その価値や文脈を大きく損なうからです。
日付データがもたらす分析価値
情報の信頼性評価: 最新の記事か古い記事かによって、その情報の信頼性や参照価値が大きく変わります。日付なしでは「今でも有効な情報なのか」判断できません。
因果関係の特定: 「Aという出来事の後にBという現象が起きた」という時間的前後関係を正確に把握することで、PRアクションの効果測定が可能になります。
生成AIを活用したニュース分析では、AIが日付情報を正確に理解することで、時間軸に沿った文脈理解が可能になります。
例えば「○○企業の△△製品に関する報道が先週から急増している」といった時間的変化を捉えた分析が可能になります。
そのため、記事取得時には必ず公開日・更新日の両方を取得し、国際標準のタイムスタンプ形式(ISO 8601形式:YYYY-MM-DDThh:mm:ss+09:00)で保存することをお勧めします。このフォーマットはデータ分析ツールや生成AIとの親和性も高く、後の分析作業を格段に効率化します。
①ニュースを探す
このプロセスは各種クリッピングサービスなど、外部サービスを利用すると容易に記事データを取得することができます。
ニュース処理にあたり、日付の処理は最も重要な処理の一つです。いつ更新されたニュースなのか集計やフィルタリングする場合のためにも、日付は必ず取得しておきましょう。
データ取得手法:
A.検索クエリで探す
オーソドックなのは検索クエリで探す方法です。
SerpAPIやSearchAPI、Brave APIなどで特定の検索クエリを対象として、データを取得する方法となります。
【主要なニュース検索API】
- SerpAPI:Google検索結果を構造化データとして取得
- SearchAPI:複数の検索エンジンに対応した汎用API
- Brave Search API:プライバシー重視の検索エンジンAPI
- NewsAPI:世界中のニュースソースから記事を取得
- Google News API:Googleニュース専用の検索API
検索クエリの設計では、以下のポイントが重要です。
・企業名・ブランド名の表記ゆれを考慮(例:「ガーボンズ」「Garbons」「株式会社ガーボンズ」)
・AND/OR検索の活用(例:「ガーボンズ AND (新製品 OR リリース)」)
・除外キーワードの設定(例:「-求人 -採用」で採用情報を除外)
・期間指定(例:「after:2024-01-01」で2024年以降の記事のみ)
APIを使用する際は、レート制限や料金体系に注意が必要です。多くのAPIは月間リクエスト数に制限があり、超過すると追加料金が発生します。
B.特定ページから探す
例えばYahooニュースだけを対象としたい場合は、サイト内検索でクエリを入力させて検索する方法なども取れます。
Yahooニュースから「大阪万博」でデータを取得するURL

「大阪万博」の検索結果 - Yahoo!ニュース
「大阪万博」の検索結果。Yahoo!ニュースでは、新聞・通信社が配信するニュースのほか、映像、雑誌や個人の書き手が執筆する記事などを掲載しています。
Yahoo!ニュース
また、特定メディアに絞った検索には以下のような方法があります。
【主要ニュースサイトの検索URL例】
・日経新聞: https://www.nikkei.com/search?keyword={検索ワード}
・朝日新聞: sitesearch.asahi.com/…arch/sitesearch.pl

・東洋経済: toyokeizai.net/search
この手法のメリット:
・特定メディアの論調を重点的に分析できる
・メディアごとの記事掲載基準を理解しやすい
・競合他社の露出傾向を媒体別に把握可能
デメリット:
・サイトごとにHTML構造が異なるため、スクレイピング処理が複雑
・robots.txtによる制限がある場合がある
・頻繁なアクセスはIPブロックのリスク
C.検索クエリそのものを生成AIに作らせる
従来のクリッピングサービスは、指定したキーワードに合致する記事を収集する点では効率的でした。しかし、「どのキーワードで探せば、本当に重要な情報を見つけられるのか?」というキーワード設定自体の難しさや、キーワードに含まれないが文脈的に重要な記事の見逃しという課題がありました。
このあたりも生成AI時代は、全く異なるアプローチが可能です。生成AIでは探したいキーワードそのものを生成させる、ということも可能になりました。
【生成AIを活用した検索クエリ生成の実例】
プロンプト例:
「弊社は〇〇業界でAIソリューションを提供している企業です。競合動向を把握するため、以下の観点で検索クエリを20個生成してください:
- 競合他社の新製品・新サービス
- 業界の技術トレンド
- 規制・法改正の動向
- M&Aや提携のニュース」
生成AIは業界知識と文脈理解を組み合わせて、人間では思いつかないような関連キーワードを提案します:
・「AI 〇〇業界 デジタルツイン」(技術トレンド)
・「〇〇省 AI活用 ガイドライン」(規制動向)
・「〇〇業界 スタートアップ 資金調達」(競合動向)
さらに、検索結果をフィードバックすることで、クエリを継続的に改善: 5. 初期クエリで検索実行 6. 取得記事を生成AIに分析させる 7. 「より関連性の高い記事を見つけるための追加クエリ」を生成 8. 1-3を繰り返し、検索精度を向上
この手法により、従来の固定キーワード方式では見逃していた重要情報を効率的に収集できるようになります。
②中身を読む
各生成AIモデルが実際にどれだけ正確にニュースを取得できるかは、6モデルを同一条件で比較した記事にまとめています。
記事を探し出した後は、実際の記事の中身を読み、判断(場合によっては分類)していくプロセスになります。
ここは従来人間が一つ一つ手作業で行ってきたプロセスですが、生成AI時代は「記事を読む」というプロセス自体をAIに担ってもらうことが可能になりました。
特に、近年従来苦手であった日本語特有でもある縦書きの記事も認識できるようになりました。ClaudeやGPT-4Vなどのマルチモーダルモデルは、スクリーンショットやPDFをそのまま読み込んで内容を理解できます。
【記事取得のアプローチ】
URLがわかっている場合:
・生成AIのWebブラウジング機能を使用(ChatGPTのWebPilot、ClaudeのWebフェッチ機能等)
・スクレイピングツールとの連携(BeautifulSoup、Playwright等)
・プログラマティックなAPI呼び出し
URLがわかっていない場合:
・検索結果からURLを取得後、上記手法を適用
・ニュースアグリゲーションサービスのAPIを活用
・複数の情報源を統合したRAG(Retrieval-Augmented Generation)システムの構築
スクレイピングとは
スクレイピングとは、Webサイトから情報を自動的に収集する技術を指します。HTML構造を解析し、必要なデータを抽出するプロセスです。
【従来のスクレイピングの課題】
・動的サイト(JavaScriptでコンテンツが生成されるサイト)への対応が困難
・HTML構造が変更されるとスクレイピングコードの修正が必要
・アクセス制限やCAPTCHAへの対応
・大量データ取得時のパフォーマンス問題
生成AI時代のスクレイピング
生成AI時代においては、従来の課題を大幅に解決する新たなアプローチが可能になりました。
【生成AIを活用したスクレイピングの利点】
-
柔軟な情報抽出:
・HTML構造が変わっても、文脈から必要情報を抽出可能
・「日付」「タイトル」「本文」等を自然言語で指定できる
・複雑なセレクタを書く必要がない
-
マルチモーダル対応:
・スクリーンショットから直接情報抽出
・PDFや画像化された記事も処理可能
・図表やグラフの内容も理解・数値化
-
コード生成の自動化:
・「このサイトからニュース一覧を取得するPythonコードを書いて」で実装
・エラー処理やリトライ処理もAIが提案
・各サイトに最適化されたコードを生成
【実装例:Python + OpenAI API】
# シンプルな例:記事ページから情報を抽出
import requests
from openai import OpenAI
client = OpenAI()
url = "https://example.com/news/article"
html_content = requests.get(url).text
response = client.chat.completions.create(
model="gpt-4",
messages=[\
{"role": "system", "content": "以下のHTMLから記事のタイトル、日付、本文をJSON形式で抽出してください"},\
{"role": "user", "content": html_content}\
]
)
③判断/要約/分析する
ネガポジ分析や文章の要約、そこに書いてある記事論調の評価などは、生成AIが最も得意なタスク範囲の一つでもあります。
生成AIを活用した分析では、大量の記事を短時間で処理し、一貫した基準で評価できることが大きなメリットです。従来、人手ではサンプル調査に留まっていた分析が、全数調査へと拡大できます。
要約
記事の要約は、広報担当者が最も時間を費やすタスクの一つです。生成AIを使うことで、以下のような高度な要約が可能になります。
【要約の種類と活用例】
- 単純要約:記事の主要ポイントを3〜5行でまとめる
- 構造化要約:「背景」「主張」「根拠」「結論」に分けて整理
- エグゼクティブサマリー:経営層向けにビジネスインパクトを中心に要約
- 比較要約:複数記事を比較し、共通点・相違点を抽出
【要約プロンプトの例】
def summarize_articles(articles):
summaries = []
for article in articles:
prompt = f"""
以下の記事を3つの観点で要約してください:
1. 主要な事実(What)
2. 背景と理由(Why)
3. 影響と示唆(So What)
記事:{article['content']}
"""
summary = ai_client.generate(prompt)
summaries.append({
'article_id': article['id'],
'summary': summary,
'key_points': extract_key_points(summary)
})
return summaries
ネガポジ分析
ネガポジ分析(センチメント分析)は、記事の論調や読者の反応を定量的に把握するための重要な手法です。
【分析の精度向上のための工夫】
-
文脈を考慮した分析:
・「いい」という単語も、「いいね!」と「いい加減にしろ」では真逆の意味
・生成AIは文脈を理解して判断可能
-
多角的な評価軸:
・単純なポジティブ/ネガティブだけでなく、「中立」「混在」なども含めた5段階評価
・「好意度」「関心度」「信頼度」など複数の軸で評価
-
業界特性を踏まえた分析:
・医療・金融などの業界では「慎重」「安全」がポジティブ
・エンタメ業界では「話題」「炎上」も必ずしもネガティブではない
【分析結果の活用】
・メディア別の論調傾向を把握し、今後のアプローチを最適化
・ネガティブな記事の早期発見と危機管理対応
・競合他社との論調比較によるポジショニング分析
【実装例:感情スコアリング】
def sentiment_analysis(text, context=None):
prompt = f"""
以下のテキストのセンチメントを分析してください。
業界コンテキスト: {context or '一般'}
評価項目:
1. 全体的な論調(-1.0〜1.0のスコア)
2. 感情の強度(弱い/中程度/強い)
3. 主要な感情カテゴリ(喜び/怒り/悲しみ/恐れ/驚き/嫌悪/信頼/期待)
4. 論調の根拠となる表現
テキスト: {text}
"""
result = ai_client.analyze(prompt)
return parse_sentiment_result(result)
Thinkingモデルの活用
2024年末に登場した「Thinkingモデル」(Claude 3.5 Sonnetやo1など)は、複雑な分析タスクにおいて大きな威力を発揮します。
【Thinkingモデルの利点】
・複数の観点からの多面的分析
・論理的な推論プロセスの透明性
・矛盾した情報の検証と統合
【活用例:複雑な論調分析】
「弊社の新製品について、表面的には肯定的だが、懸念も示唆されているような記事の場合、どのように評価すべきか」
Thinkingモデルは、表面的な表現だけでなく、文章構造、使用されている言葉の選択、引用されている情報源などを総合的に判断して、より正確な論調分析を提供します。
【高度な分析タスクへの応用】
-
競合分析:
・複数企業の記事を横断的に分析
・市場でのポジショニングを多角的に評価
・隠れた競合関係の発見
-
リスク予測:
・過去の類似事例との比較分析
・潜在的なリスクの早期発見
・対応優先順位の提案
-
トレンド分析:
・表面的な流行と本質的な変化の区別
・業界の構造的変化の予測
-
・新たなビジネス機会の発見
def deep_analysis_with_thinking(articles, query):
context = prepare_context(articles)
prompt = f"""
以下の記事群を分析し、{query}について考察してください。
分析の際は以下の観点を考慮してください:
1. 表面的な論調と深層的な意図の違い
2. ステークホルダーごとの視点の違い
3. 時系列での変化とその要因
4. 他の事例との比較から見える特徴
記事データ: {context}
【実装のポイント】
# Thinkingモデルを使った深い分析の例
データベース活用でより堅牢に
意外に重要なのが、データベースの活用です。
業務で活用する際は、毎日・毎週などの定期的調査が必要となるケースがほとんどです。
【データベース活用のメリット】
-
重複処理の回避:
・一度取得・分析した記事を記録し、再処理を防ぐ
・更新日時を管理し、差分処理を実現
-
時系列分析:
・間編推移を追跡し、トレンドを把握
・異常値検知(突然の記事数増加など)を自動化
-
関連性分析:
・記事間の関連性を分析
・トピックの波及効果を測定
【実装上のポイント】
・ベクトルデータベース(Pinecone、Weaviate等)との連携でRAGを実現
・将来のMCP連携を考慮
生成AI時代における広報PRの変化
生成AIの登場により、広報PR業務は大きな変革期を迎えています。単なる効率化を超えて、戦略的な意思決定のあり方自体が変わりつつあります。
【変化のポイント】
-
リアクティブからプロアクティブへ:
・問題発生前にリスクを予測・対処
・トレンドを先読みしたコンテンツ戦略
-
定性から定量へ:
・感覚ではなくデータに基づいた意思決定
・ROIの可視化と最適化
-
局所最適から全体最適へ:
・各メディア対応から統合的コミュニケーションへ
・ステークホルダー全体を俯瞰した戦略立案
データドリブンな広報戦略
【具体的な活用方法】
①記事データやメディアリレーションズデータをRAGに使う
RAG(Retrieval-Augmented Generation)を活用することで、過去の記事データやメディア対応履歴をAIに学習させ、より精度の高い分析や提案が可能になります。
例えば:
・「過去に同様の問題が起きた際の対応方法を教えて」
・「このメディアの傾向を踏まえたアプローチを提案して」
・「成功したプレスリリースのパターンを分析して」
②MCP(Model Context Protocol)を活用する
Anthropic社が提供するMCPを使うことで、生成AIが直接データベースや外部ツールにアクセスできるようになります。これにより、リアルタイムでの情報収集・分析が可能になります。
活用例:
・メディアモニタリングツールとの連携
・CRMシステムとの統合
・ソーシャルメディア分析ツールとの接続
海外事例
【先進例:米国大手テック企業のPR部門】
・24時間365日のメディアモニタリングをAIで自動化
・ネガティブシグナルを早期検知し、危機管理チームにアラート
・ROIをリアルタイムで計測し、予算配分を最適化
【欧州企業の事例】
・GDPRに準拠したプライバシー保護を前提としたシステム設計
・多言語対応の自動翻訳・ローカライズ機能
・各国の文化的コンテキストを考慮したセンチメント分析
注意点
【技術的な注意点】
-
API利用料の管理:
・大量の記事を処理する場合、API料金が高額になる可能性
・バッチ処理やキャッシュの活用でコスト削減
-
データ品質の確保:
・HTML構造の変更に対応できる柔軟な設計
・エラーハンドリングとリトライ処理の実装
-
倖理的配慮:
・人間の判断が必要な場面を明確化
・AIの判断基準を透明化し、説明可能性を確保
各社の著作権に関して
オールドメディアの対応は非常に遅く、未だ生成AIに入力することすらNGとしているメディアが多いです。
しかし時代はすでに人間が記事を読む時代から、AI(エージェント)が記事を読む時代への進化しています。
これらのルールはすぐに変更されることでしょうから、今から準備しておくのが良いかと思います。
参考までに各新聞社などの生成AIへの対応です。
日経新聞
日経コンテンツを許可なく データマイニング、テキストマイニングおよびAI開発を目的としたディープラーニングなどの情報処理、情報解析またはAI学習その他の処理のために、蓄積、複製、加工その他の利用を行うことはできません。
日本経済新聞 ヘルプセンター
www.nikkei.com
読売新聞(ヨミダス)
6.利用者は、本サービスで出力した本記事等を、クローリング、スクレイピング等の自動化された手段を用いたデータ収集・抽出・加工・蓄積その他コンピューターによる情報解析またはデータマイニング、テキストマイニング等のコンピューターによる言語解析のために利用することはできません。本データ等を手動で収集・抽出・加工・蓄積して情報解析または言語解析のために利用することもできません。
7.利用者は、本記事等を短時間で大量に表示し、または当社が必要と認める限度を超えて本記事等を大量にダウンロードすることはできません。 8.利用者は、 生成AI等(人工知能、検索拡張生成、RPA、ロボットを含みますが、これらに限られません。以下同じ)に学習させる目的、または生成AI等を開発する目的で、本サービスを利用(結果的に第三者の生成AI等に学習させることとなる利用を含みます)することはできません。
読売新聞 マーケティング(PDF資料)
ma.yomiuri.co.jp

朝日新聞
(8)デジタル版について、当社の事前の書面による許可なく、 データマイニング、ロボット等によるデータの収集、抽出、解析または蓄積等をする行為 、及びAIの開発・学習・利用またはその他の目的のために、情報・データの収集、抽出、解析または蓄積等をする行為
朝日新聞デジタル利用規約 - 総合ガイド
パソコン、スマートフォン、タブレットで読める朝日新聞のデジタル版「朝日新聞デジタル」の利用規約です。
朝日新聞デジタル