生成AI / LLM
生成AI技術は様々な分野で革新をもたらしていますが、その活用にはプログラミングスキルが必要とされ、多くの非エンジニアにとっては恩恵を受けにくい現状があります。
このような技術格差の解消も期待されている、ノーコードAIアプリケーション「Dify」に今注目が集まっています。本記事では、特に 非エンジニアの視点から (やってみた系でなく)、Difyを活用するためのポイントや勘所、つまずきポイントなどを解説していきます(Ver.は記事公開時の0.7.1を前提とします)。
本記事は以下の読者の方を対象にしています。
・Difyを使い始めたばかりで、操作や全体機能の理解に困っている方
・生成AIを活用して業務を効率化したいと考えている非エンジニアの方
Difyとは
Dify は、オープンソースのLLM(大規模言語モデル)アプリケーション開発プラットフォームです。
ノーコードで生成AIの実装や処理が可能で、直感的なインターフェースと豊富な機能を提供し、外部APIと連携することも可能なため、様々な複雑な処理が可能です。
LLM界のピタゴラスイッチ/インクリディブルM
Difyは例えていうなれば、古くはインクリディブルマシーン、最近で言えばピタゴラスイッチに似ているといえます。
Difyではこれらの世界のように、モノとモノを組み合わせ、レゴブロックのように自分が作りたい機能をつなぎ合わせ、自動化して実行することができます。
ルーブ・ゴールドバーグ・マシン として、バック・トゥ・ザ・フューチャーやグーニーズなどのオープニングでもお馴染みです。
この自動化プロセスに「生成AI」が組み合わさったことで、従来は時間と労力を要していた複雑処理や、高度な人間の判断・解釈が必要とされていたタスクも、より効率的に構築し実行できるようになりました。
ホワイトカラーのデスクワーク仕事が無くなると言われている所以でもあり、これまでPCを使って行われてきたデスクワークの大半は、今後LLMアプリケーションで代替することが可能となるでしょう。
なぜDifyか
LLMアプリケーション開発プラットフォームの中で、なぜDifyなのかという説明も簡単に触れておきます。
【特長①】ノーコードで各社のLLMを使える

ChatGPTやClaudeなどのWebブラウザを通しての生成AIサービスは、操作が簡単な反面、大量のデータ処理や細かなパラメーター調整などが難しいです。
そこでこうした処理にはコードを使い、APIを通して複雑処理を行うわけですが、これが結構面倒です。特に生成AIはモデルが頻繁に更新されたり、各社でパラメーターやコーディングプロセスが少しずつ異なるため、一つ一つを細かく修正、評価するのが非常に面倒です。
こうした 各社バラバラであったLLMを、ブロック1つで使えるようにしたのがDify であり、そしてLLMだけでなく様々な拡張機能を ブロック単位で簡単に繋げることができる 点がDify最大の特長です。
【特長②】 圧倒的にRAGに強い
RAG(Retrieval-Augmented Generation)とは、検索AIと生成AIを組み合わせた技術で、簡単にいうと 「AIにカンニングペーパーをカンニングさせながら回答させる方法」 です。
正解が分かれば最初から苦労しないじゃないかと思われる方もいるかもしれませんが、膨大なデータの中から 「正解に近いデータ(ヒント)をどう探してくるか」 が鍵となるのです。
RAGは以下の3ステップで動作します。
- ”正解”やヒントを事前にデータベースとして数値化して保存しておく
- 質問を数値化し、回答の前に類似データを検索する
- 検索結果を質問の中に入れて、AIに回答を生成してもらう
流れとしては以下の様な流れとなります。
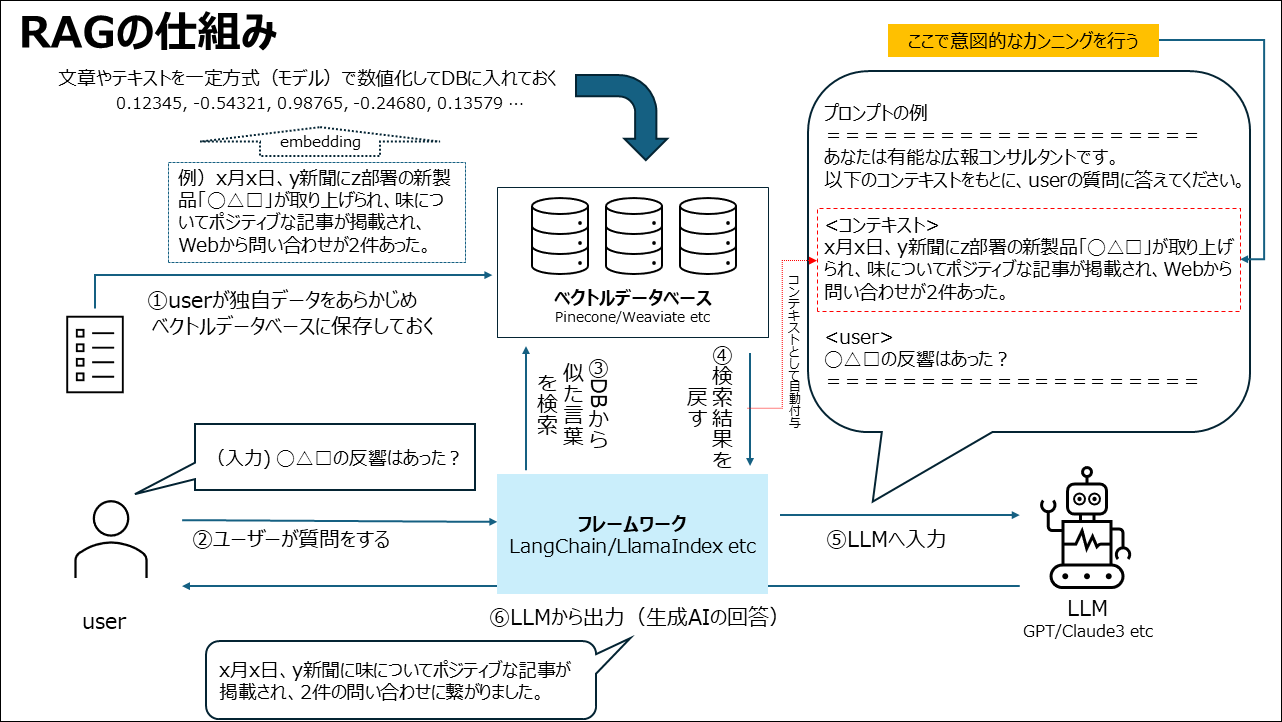
RAGは生成AIのなかで、有効性・有用性が高い技術であり生成AIの精度向上のための主流となりつつある技術のため、(一過性のプロンプトエンジニアリングとは異なり)学習コスパも大きいのではないかと思います。
このRAGのプロセスには
- 情報のベクトル化(コードとLLMモデルを使って全てのデータを切り分けて数値化する)
- ベクトルデータベースでの情報管理(ベクトルデータに特化したDBサーバーで管理する)
といった2つのプロセスが必要で、それが技術的な大きな障壁となっていました。
Difyではこのプロセスもノーコードで簡単に実行することが可能です。
また最新のバージョンでは「Firecrawl」などのツールを使えば、テキストデータだけでなくURLを介してWebサイトをクローリングさせ、その内容を自動的にRAG化することもできるようになりました。
Webサイト一つあれば、自社の専用知識を保有したチャットボットやカスタマーボットを作ることができるわけです。
【特長③】開発が爆速でコミュニティも活発
Difyを動かしているソースコードはオープンソースとして全て公開されており、ユーザーコミュニティも賑わっています。
Githubでの高いスター数が示すように、多くのユーザーや開発者の支援を受けており、これが週単位でのマイナーアップデートを可能にしています。
この迅速な開発サイクルにより、最新ツールや重要な実装が次々と追加されていきます。
[Dify Discordコミュニティ](https://discord.com/invite/5AEfbxcd9k)sangmin.eth \| 安全なう @gijigae
— sangmin.eth \| 安全なう (@gijigae) 午後1:08 · 2024年8月22日
【特長④】拡張性の高さ
様々な外部ツールと連携させることができ、自由度の高いこともDifyの魅力の一つです。
似たようなツールにOpenAIのGPTsというものがありました。このGPTsはツール設定が10個までしかできず、動作ももたついたり、比較的出力も不安定で、パラメーターも調整できないなどDify登場後は色褪せてしまっています。
そうした中、DifyはこのGPTモデルだけでなくGeminiやCohere、LlamaといったAPIが公開されている数多くのLLMモデルを使うことができます。
そして 「カスタムツール」を使えば、外部APIとの連携も柔軟で思い通りの操作が可能 です。
以下でも解説したように「エージェント機能」を使えば、一般公開されていない独自ツールでも自分でAPIサーバーを立ててしまえばAI経由でいくらでも使うことができるのです。
【Dify活用】生成AIでSNSの投稿を爆速で作成する方法②エージェントの活用Dify技術を活用したSNS投稿作成の効率化方法(②エージェントの活用)を解説します。広報・PR支援の株式会社ガーオン
【特長⑤】オープンソースでデータ機密性を担保
LLMで最も重要なポイントの一つとしても上げられるのがデータの機密性保持です。
初期のブラウザ版ChatGPTなどは、入力データを学習データとして使うようにディフォルト設定されており、どこまで機密情報を入力してよいか、また従業員に安心して使わせられるかの観点から大きな課題となっていました。
大手企業などはこの点をクリアするために、マイクロソフトのサーバー環境でGPTモデルをAPI経由で独自に活用して利用するなどの対応を取っています(APIは入力データを学習に使わないとOpenAIは説明している) 。
しかし中小企業にはこのような大きなコストがかかる施策は無理があります。
Difyは有料のクラウド版で使うこともできますが、ローカル版を使ってPCにインストールすれば、インターネットに介すことなく、かつ 無料 で使うことができます。
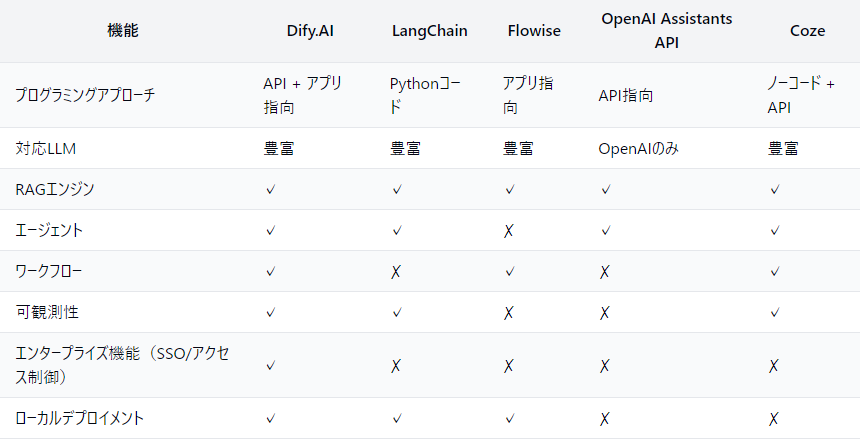
比較表(Difyより)※翻訳し一部追記
非エンジニアやマーケターが活用すべき理由
LLMは全ての業務領域の生産性を変える画期的なテクノロジーです。
この魔法のようなテクノロジーを、エンジニアや一部の専門家だけのものにしてはせっかくのビジネスチャンスを狭めてしまいます。
LLMは、あらゆる部門や職種で革新的な変化をもたらす潜在力を秘めています。
これは生成AIブーム前にも言われていましたが、現場を理解しており ドメイン知識が豊富な非エンジニアがAIツールを積極活用することで、業務生産性は大幅に上がる ことでしょう。
Dify活用のコツと絶対つまずくだろうポイント
ここからは非エンジニア向けに、Difyの活用ポイントとつまずきポイントを解説します。
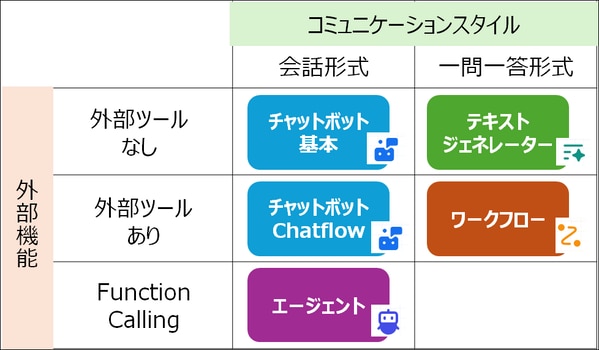
ポイント①全体像の理解
Difyは機能が多い一方で、メニューの分け方や構成が少し分かりづらい(テキストジェネレーターが急に出てくるなど)部分があるため、最初は全体像を掴むのに時間がかかってしまいます。
まずアプリ種別が3種あり、その下にChatflowやワークフローなどのメニューがあるという階層構造で理解すると分かりやすいかと思います(メニュー画面の構造は忘れたほうが良いかもしれません)。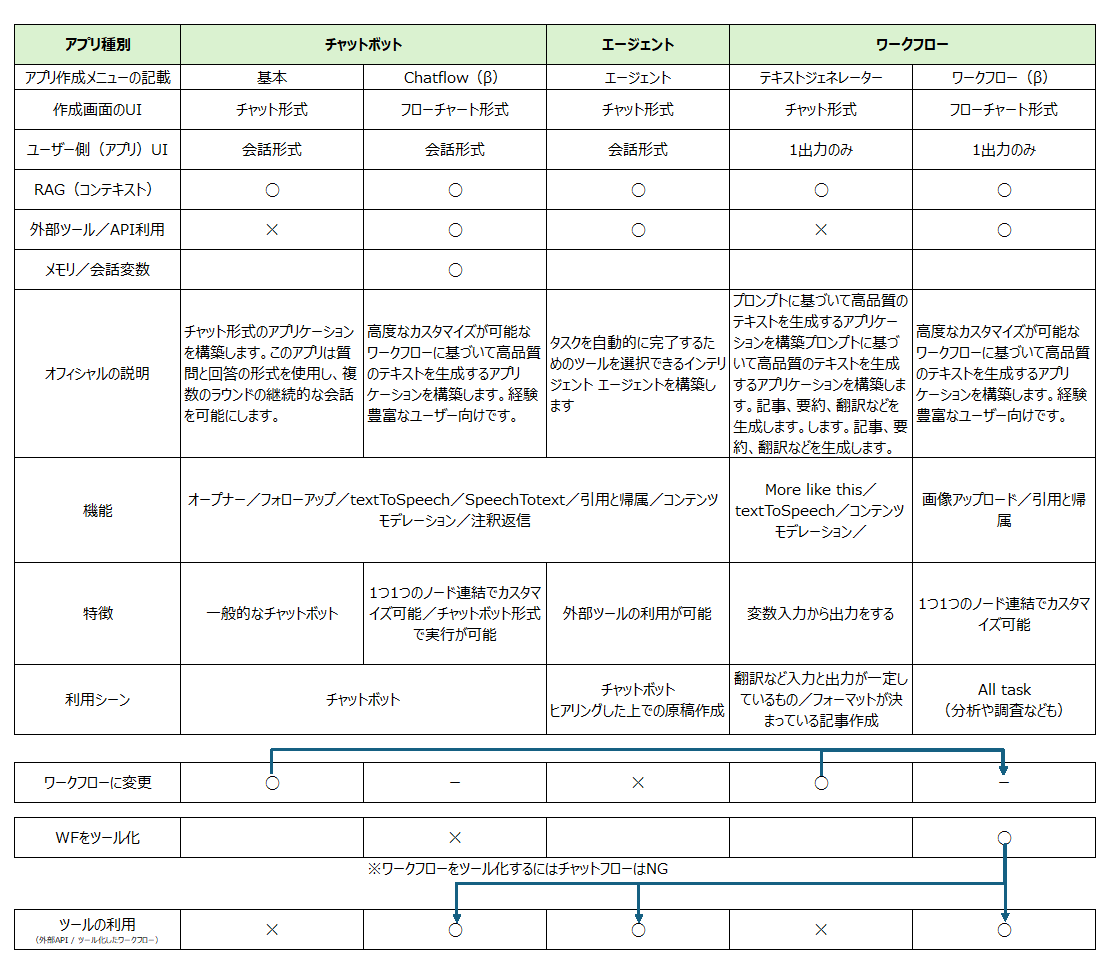
使い分けポイントは、
- 出力形式が会話形式か1回限りでも良いかどうか
- 外部ツール(APIなど)が使えるかどうか
です。
チャットボット/エージェント/ワークフローの違いは、以下記事でも少し触れています。
Difyにプレスリリースを自動作成させる方法ノーコードLLM構築ツールDifyでプレスリリース作成業務を自動化する方法を解説します。広報・PR支援の株式会社ガーオン
ポイント②ブロックの「入力」と「出力」を意識する
Difyはブロック単位で組み合わせて構築していきます。
この全てのブロックにおいて、「入力データ」と「出力データ」が必要となります。
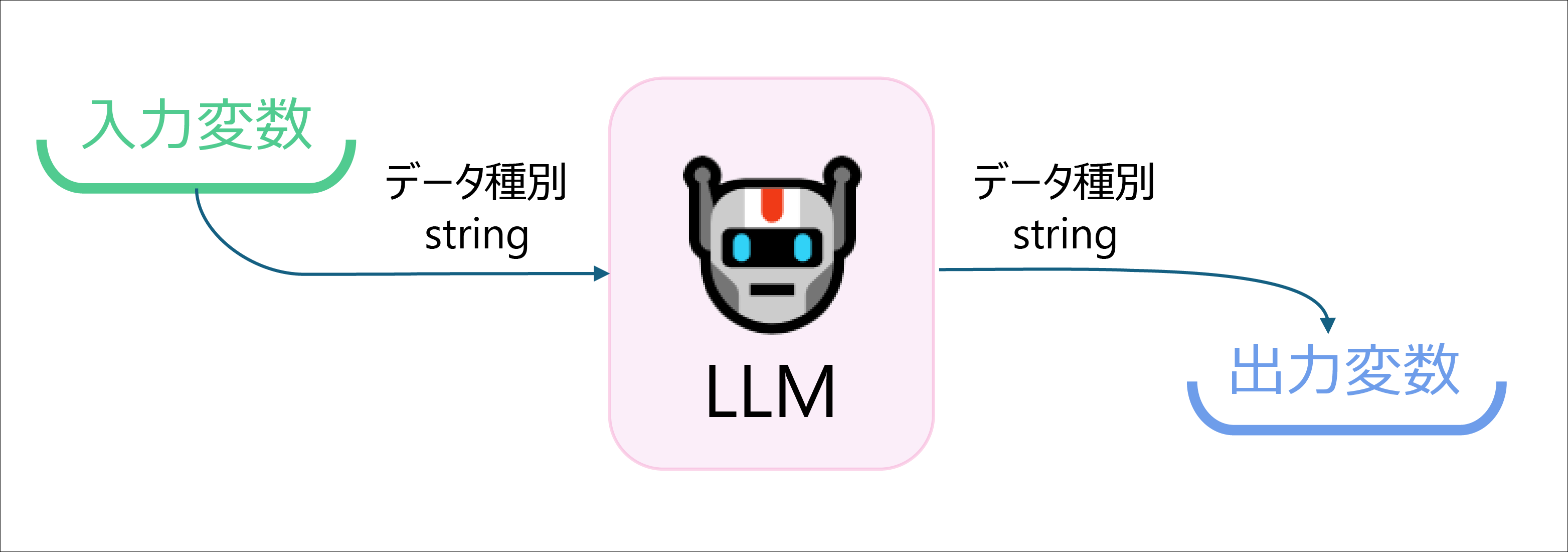
図で示すとこのようなイメージです。これを以下のように数珠つなぎのように繋げていくわけです。
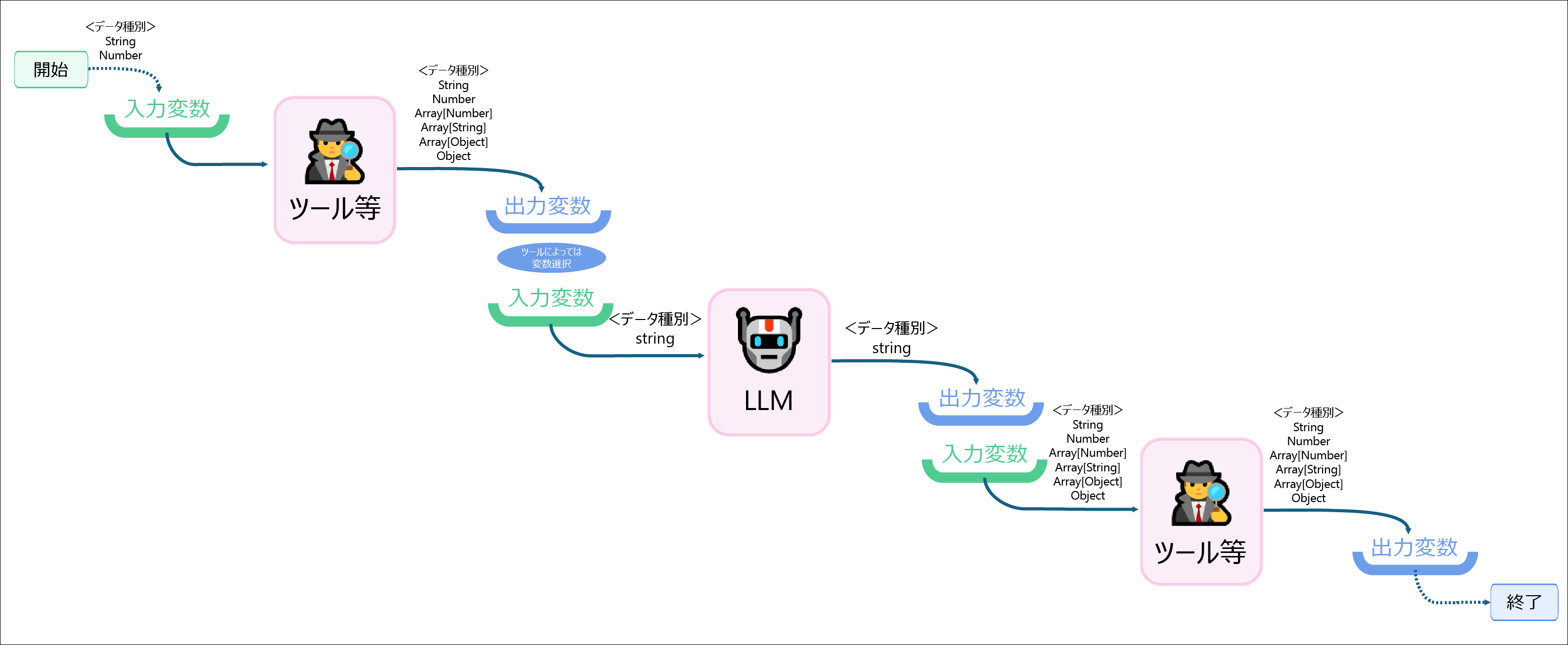
ブロックで入出力を繰り返すDifyは伝言ゲームのようなもの です。
そしてこの「入力」と「出力」には、型(データタイプ/拡張子のようなもの)が存在します。
あるブロックの出力は、あるブロックの入力となります。
そしてこの入力と出力それぞれの 「データ型」が一致していないとエラーとなってしまう のです。
これはプログラミングに触れている人には当たり前かもしれませんが、最初につまずくポイントで、意外と理解しずらい箇所かと思われます。
ポイント③データの型を理解する
最初と最後以外の中間ブロックには必ず「入力変数」と「出力変数」があります。
この入れ物に入るデータ型の種類を理解をすることが次のポイントとなります。
Difyに記載されている主な変数のデータ型区分
- String
- Number
- Array[Number]
- Array[String]
- Array[Object]
- Object
これらはjson文字列の型を示していると考えられます。
続いて、出力変数の一データ型の一例を確認してみます。
出力変数の一例(firecrawl)

今度は「text」「files」「json」と新しいワードが出てきました。
Difyではこのファイルタイプとして、JSONというものを理解しておく必要があります。しかしDify上の表記方法は、(MECEでない部分もある?)かなり混乱する記載方法のため厄介なのです。
このあたりを生成AIに聞いても、最初から明確な定義で使われていないため、ルールを掴むことがなかなか難しい状況になってしまうのです。
ちなみにJSONは大きく以下の3つの意味で使われるようです。
JSON文字列:
意味:データを表現するテキスト形式 特徴:文字列としてのJSON。キーと値のペアがダブルクォートで囲まれ、カンマで区切られています 例:'{"name": "John", "age": 30}' JSONオブジェクト: 意味:プログラミング言語内でJSONデータを扱うためのデータ構造 特徴:言語固有のオブジェクトまたはデータ構造として表現されたJSON 例:JavaScriptの場合 {name: "John", age: 30} JSONモジュール: 意味:JSONデータを操作するためのプログラミング言語のライブラリやモジュール 特徴:JSON文字列とJSONオブジェクトの相互変換、JSONの読み書きなどの機能を提供 例:Pythonのjsonモジュール、JavaScriptのJSONオブジェクト これらは確かに異なる概念ですが、互いに密接に関連しています: JSON文字列は、データの保存や転送に使用されます。 JSONオブジェクトは、プログラム内でデータを操作する際に使用されます。 JSONモジュールは、JSON文字列とJSONオブジェクトの間の変換や、JSONデータの処理を支援します。
(Claude3.5sonnetの解説)
実際の流れで説明
ここからはファイルタイプがどのように影響してくるか、実際の例で解説します。
※追記:Firecrawlはバージョンによっては、textでそのまま返すようになっているようです。以下の説明は最新バージョンと異なる場合があります。
以下はワークフローで、ヤフーニュースTOPページをツール「firecrawl」でスクレイピングし、LLMで5件のニュースをピックアップして出力するというシンプルなフローです。
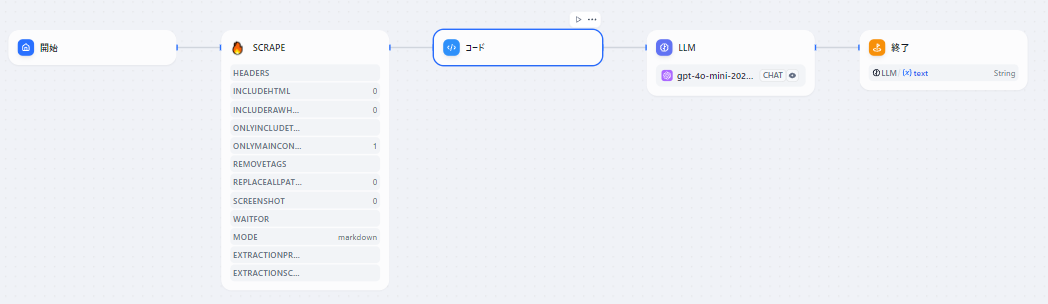
このブロックは、更に解説すると以下のようなプロセスとなります。
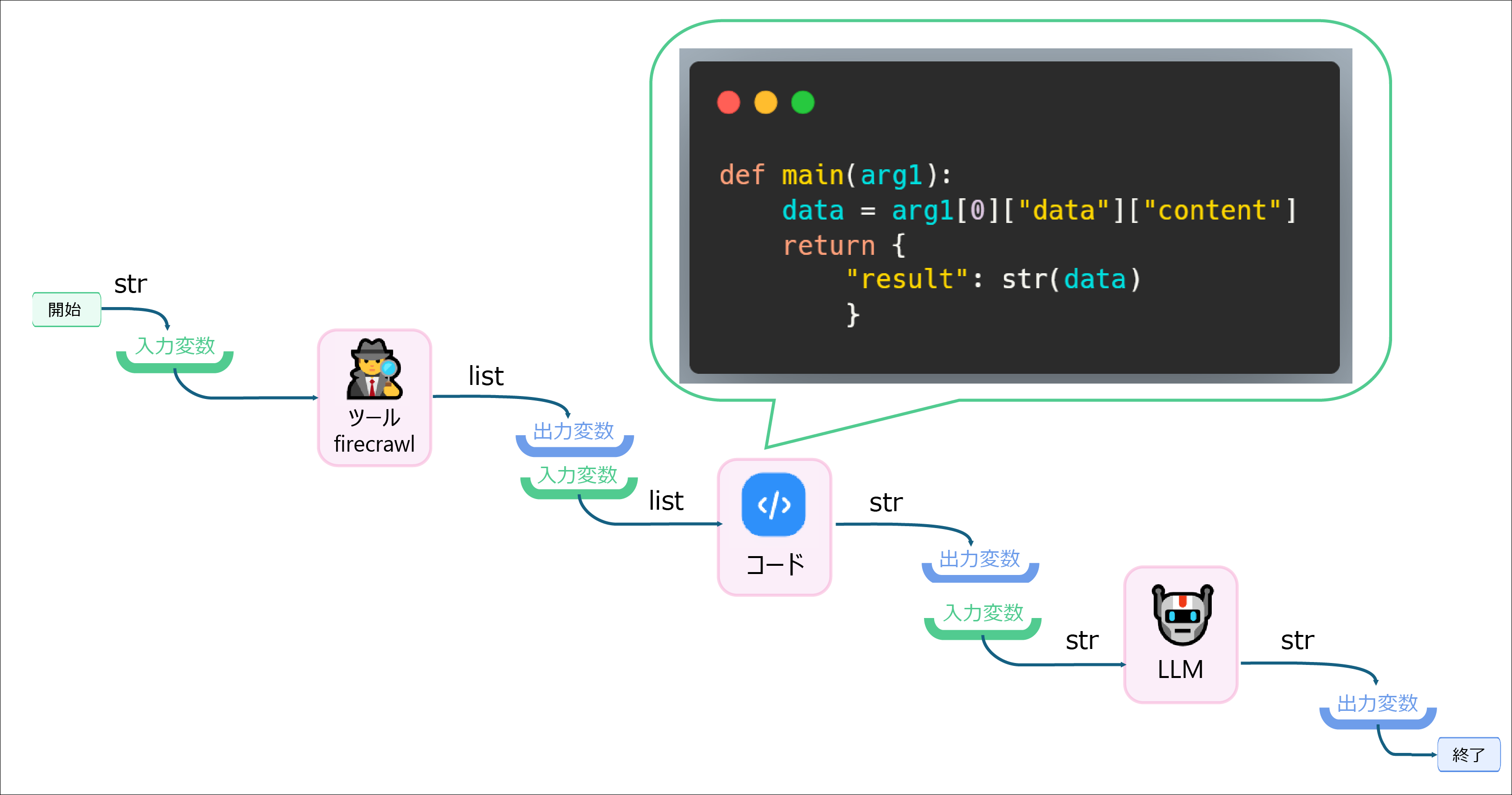
まず開始ブロックでURL(str/文字列)を入力します。ツール(firecrawl)がこの入力をもとにスクレイピング処理を行い、出力データを出力します。
このときの出力データはDifyの画面には以下のように記載されています。
実際のデータは以下のような構造です。
{
"text": "",
"files": [],
"json": [
{
"success": true,
"data": {
"content": "トピックス\n-----\n\n* [台風10号の影響長引く 週末も警戒](https://news.yahoo.co.jp/pickup/6512253)\n \n* [新幹線で一部運休 バス乗り場行列](https://news.yahoo.co.jp/\
このデータ自体は「Pythonオブジェクト(dict/辞書型)」です。
そして、次のブロックにはコードブロックを用意していますが、このコードブロックに入力できるデータは、このdictのキーとなっているtextかjsonしか選ぶことができません。
入力データが入っているjsonキーを選ぶと、この中に入っていた「Pythonオブジェクト(list/リスト型)」が入力データになります。
つまりfirecrawlは裏側で辞書型を出力してはいるが、次のブロックの入力では必然的にリスト型となるわけです
このあたりのデータ処理の流れを理解しておかないと、エラーが出たときの対応に時間がかかってしまうと思われます。
LLMの前後はstr
今回のフローは、firecrawlでスクレイピングしたデータからLLMでいくつかニュースをピックアップしてもらう流れでした。
このLLMブロックは、入出力が必ずstr(文字列)となります。生成AIは裏側では、入力データに続くテキストの予測を行っているだけですので、入力も出力も文字列となると考えると分かりやすいかと思います(複雑な処理はコード文を出力したり、アプリケーション側で関数を実行している)。
firecrawlから出力されたデータは、最終的にはリスト型になっているのでした。ここで行いたい処理は、LLMへの入力なので、どこかでstr(文字列)にしておく必要があります。
そこでコードブロックを噛ませて、リストから文字列に変えるため以下のコードを入れてあります。
def main(arg1):
data = arg1[0]["data"]["content"]
return {
"result": str(data)
}
上記コードは入力変数がlist(Pythonオブジェクト)なので、arg1[0]…などでデータのフィルタリングができますが、これがjson文字列だった場合は、json.loads()などでPythonオブジェクトに変更する必要があります。慣れていないとこの変換も混乱することでしょう。
JSON文字列とPythonオブジェクトの関係
上記のjson文字列とPythonオブジェクトの関係は以下のようにまとめられます。
LLMに入力するデータはテキストデータ(str)でないとなりません。なのでツールから出力されるデータがPython文字列だった場合は、json.loads()関数でPythonオブジェクトに変更し、その上でフィルタリングし、最終的にstrデータにしておく必要があります。
# コードブロックへの入力がjson文字列だった場合
def main(arg1):
import json # jsonモジュールをインポートします。
json_data = json.loads(arg1) # json.loads()関数を使って、JSON文字列をPythonの辞書型オブジェクトに変換します。
data = json_data[0]["data"]["content"] # 変換された辞書型オブジェクトから、必要なデータを取得します。
return {
"result": str(data) # 取得したデータを文字列に変換し、結果として返します。
}
ポイント④外部ツールの活用
LLMブロック単体で使うだけでは、ChatGPTなどのブラウザアプリを使っているのとあまり変わりません。
Difyでは豊富な外部ツールをLLMブロックに連結することで、様々な処理が可能となります。下記は良く使われる「検索ツール」のツール一覧です。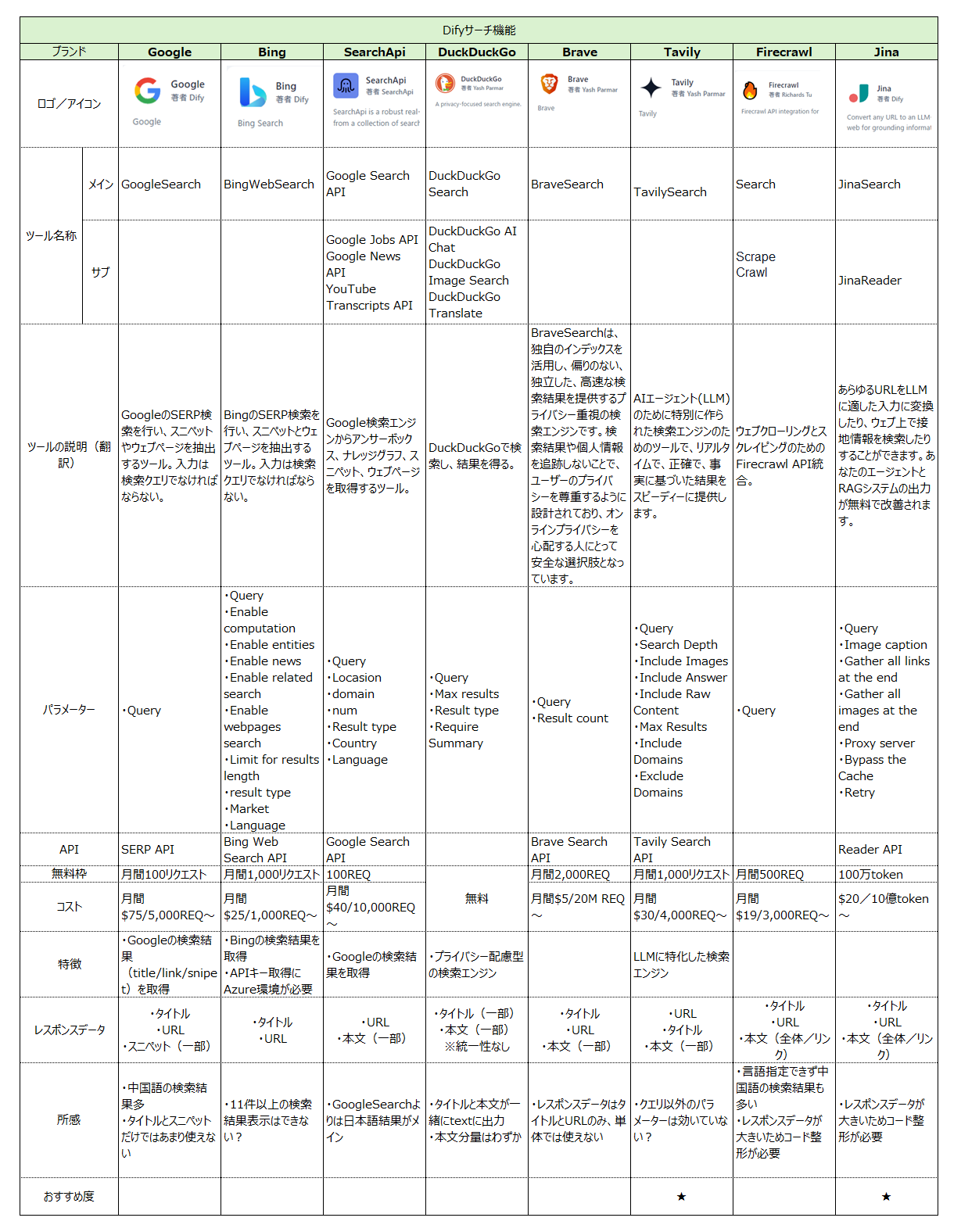
ツールが多くて(更にバージョンにより細かな変更も多い)何を使ってよいか分からなくなりますが、今までの動きを見ていると検索系は「Tavily」か「JINA Search」を使い、Webスクレイピングは「Firecrawl」を使っておけば良いかと思います。
各ツールの具体的な比較は以下の記事に記載しています。
生成AI(Dify)を活用した検索・情報収集のポイントDifyの様々な検索・情報収集ツールを実際に使い、精度を比較しながら細かく解説します。広報・PR支援の株式会社ガーオン
Firecrawlが熱い
スクレイピングツールの 「Firecrawl」 はDifyのナレッジ(RAG機能)とも連携しており、自社WebサイトのRAG化などを簡単に実行することができます。
ちょうど新しいVerも発表され開発もかなり盛んであるようなので、これからの発展も期待できます。
Twitter Embed
·
Today we are starting our first ever Launch Week! 
For this week, we’ll be releasing a new feature daily. We're saving the best for last so stay tuned 
Day 1 - Introducing Teams: Invite your co-workers to build with you in Firecrawl さらに表示

ポストへのリンクをコピー
LLMと連携させたスクレイピングも可能。下記動画ではプロンプトに「ホテルの名前・場所・レーティング」を取ってこいと指示するだけで、クラス名等の指示無しに該当項目を取得するフローが解説されています。最新Verではパラメーター無いでプロンプトなどの指示出しも完結できるようです。
ちなみにFirecrawlはオープンソース版も公開されており、ローカルで実行すると通常API利用料がかかるところを、なんと全て無料で実行することができます。またLLMを使ったスクレイピングにも対応しており、データ収集を行う全てのビジネスパーソンが今使うべきツールの一つでもあります。
ツールをAIに委ねてしまう「エージェント」機能
ちなみにAI自体にこうしたツールを持たせて、利用有無や使うタイミングなどを委ねて全てまかせてしまうのが「エージェント」機能です。
「エージェント」はFunction Callingという技術をもとに作られており、以下でも解説しています。
【まとめ】Dify活用にあたっての意外と重要なポイント
ここまでDifyの一連の機能と活用ポイントをまとめてきましたが、使ってみると意外と 「データ処理スキル」 が重要ポイントであることが分かります。
特にデータ型については、JSON文字列とPythonオブジェクトの処理に慣れていないと操作に時間がかかりますし、データが増えれば増えるほど、全体認識や細かな処理の重要性が増してくるでしょう。
Ver0.7.1の現段階では、まだまだエラー文章は分かりづらく、エラーが出てもAIは助けてくれません。まだまだ完全なノーコードとは言い難く、コーディングやデータ処理のために予想以上に時間がかかることも想定されます。
しかし、すべての企業がこうした学習コストを捻出できるわけではありません。人材や時間のリソースが限られている中で、Difyの導入やAIアプリケーション開発に大きな負担を感じる企業も多いのではないでしょうか。
学習コスト捻出が難しい企業の皆様は、ぜひ弊社にお気軽にご相談ください。Difyの専門知識と実践経験を持つ弊社チームが、お客様のニーズに合わせた効率的なソリューションをご提案いたします。
Difyの使い方(メモリ—機能と会話変数とは)Difyでつまづきそうなメモリ—機能と新たに加わった会話変数の使い方を解説します。広報・PR支援の株式会社ガーオン