「自社や競合企業の動向を効率的に収集したい」
「大量のデータをAIで自動分析させたい」
こうしたニーズを生成AIで対応するとき、重要となるのがニュース情報の取得・処理方法です。
特にRAG(Retrieval Augmented Generation(検索拡張生成))などでニュース記事を活用する際にも、最初のデータ取得時の要となります。
そんな中、ニュース記事の取得処理に特化した「 newspaper4k」というライブラリを見つけました。
本記事では備忘録も兼ね、実際のニュース記事を使って検証してみます。
プログラミング初心者の方にも分かりやすく、何ができるのか、どう使うのか、メリット・デメリット、そしてAIツールとの連携方法まで、詳しく解説します。
newspaper4kとは?AIとニュースを繋ぐ便利なツール
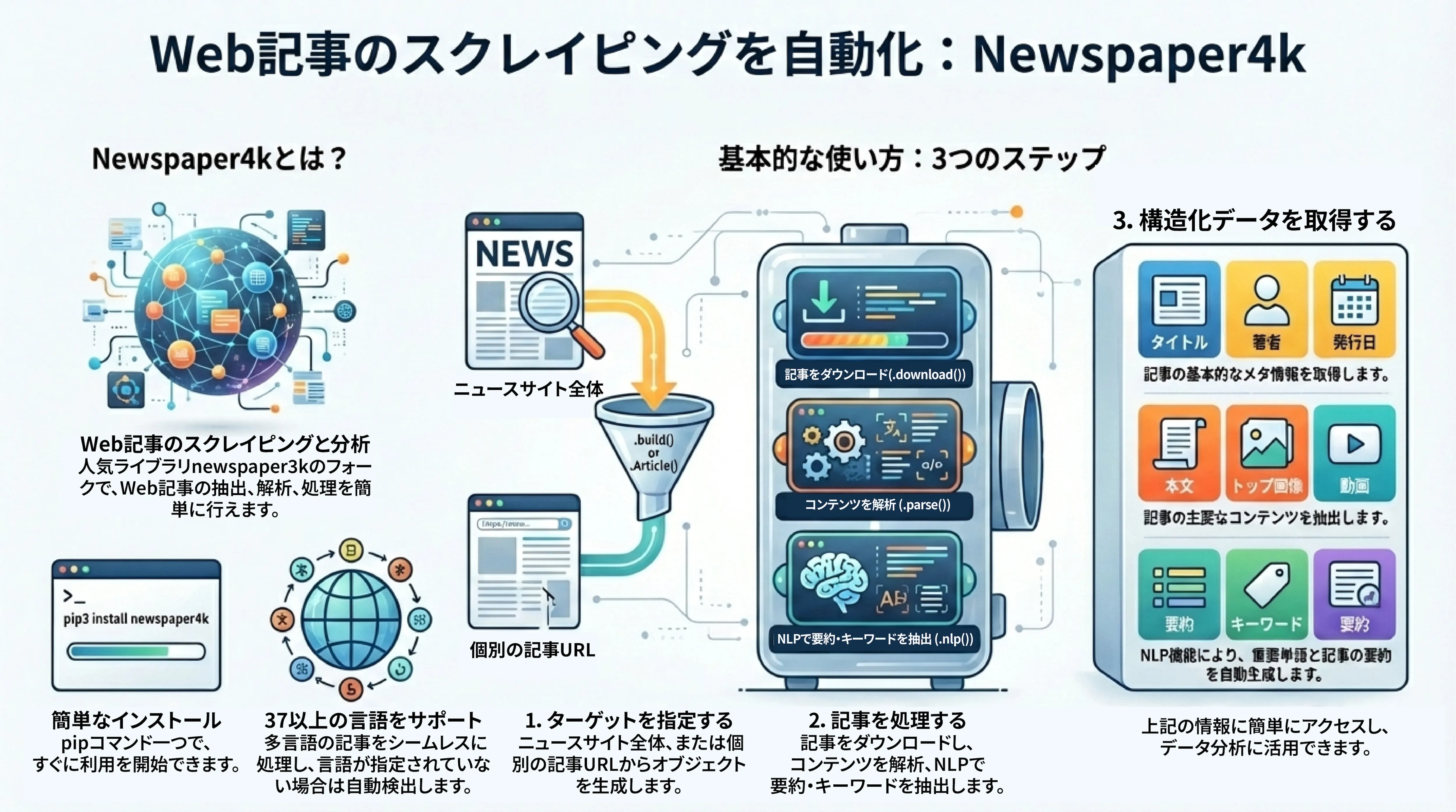
「ニュース記事から必要な情報だけを抜き出す」ライブラリ
newspaper4kは、Webサイトからニュース記事を自動で抽出し、タイトル、本文、著者、公開日、画像などを整理してくれるPythonライブラリです。
こんなことができます:
-
ニュース記事のURLを渡すだけで、タイトル・本文・著者・日付を自動抽出
-
記事の要約を自動生成
-
キーワードを自動で抽出
-
複数サイトから一括で記事を収集
-
80以上の言語に対応
誰に役立つ?
-
マーケター:業界トレンドの把握、競合分析
-
リサーチャー:大量記事の効率的な分析
-
データアナリスト:テキストデータの収集
-
開発者:ニュースアプリやAIシステムの開発
-
PR担当者:メディア露出のモニタリング
newspaper4kの誕生背景:人気ライブラリの「継承と進化」
実は、newspaper4kには前身となる「 newspaper3k」という非常に人気のあるライブラリがあったようです。
Newspaper3k: Article scraping & curation
しかし、2020年9月に更新が停止し、github上で400以上の未解決問題を抱えたままになっていました。
そこで登場したのがnewspaper4kです。
newspaper4kの特徴:
-
newspaper3kのAPIとの 完全な互換性 を保持
-
継続的なバグ修正(400+ issue → 180まで削減)
-
新機能の追加(40以上の新言語対応、Google News統合など)
-
活発な開発コミュニティ
-
最新のPython 3.10以上に対応
つまり、「人気ライブラリの良さはそのままに、さらに改良を続けているプロジェクト」なわけです。
newspaper4kで何ができる?主な機能を分かりやすく解説
今回は実際に記事後半でWebニュースを対象として、ITmediaの記事で実験してみたいと思います。
ちなみにITメディアのrobot.txtは以下となっており比較的寛容とされていますが、日経など新聞はロボットアクセスに非常に厳しくなっていますので、実行の際はくれぐれもご注意ください。Yahooニュースなどは素で叩くと403エラーとなります。
ITメディアのブロック設定(サイトマップのみ)
User-agent: * Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/googlenews_sitemap.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml Sitemap: www.itmedia.co.jp/…_sitemap_index.xml
Sitemap:
ITmedia – sitemap.xml
itmedia.co.jp
日経新聞のクローラーブロック設定
User-agent: * すべてのクローラーが対象(Google、Bingなど一般検索エンジン) Allow: /markets/kabu/stkcomp/$ 株価比較トップページのみ許可($=URL末尾一致) Allow: /markets/kabu/gyoshucomp/$ 業種比較トップページのみ許可(同上) Disallow: /.tools 内部管理ツール禁止(セキュリティ保護) Disallow: /markets/kabu/stkcomp/ 株価比較の詳細ページ禁止(有料会員コンテンツ保護) Disallow: /markets/kabu/gyoshucomp/ 業種比較の詳細ページ禁止(同上) Disallow: /.resources/k-components/rtoaster/ トラッキングシステム禁止(技術的ファイル) User-agent: CCBot Common Crawl(GPT学習用データ収集)全ページブロック User-agent: GPTBot OpenAI公式クローラー全ページブロック User-agent: ChatGPT-User ChatGPTユーザーのブラウジング機能全ページブロック User-agent: Google-Extended Google Bard/Vertex AI学習用全ページブロック User-agent: anthropic-ai Anthropic学習用クローラー全ページブロック User-agent: cohere-ai Cohere言語モデル学習用全ページブロック User-Agent: omgili Omgiliニュース収集全ページブロック User-Agent: omgilibot OmgiliBot全ページブロック User-Agent: ICC-Crawler ICCデータ収集クローラー全ページブロック User-agent: Applebot-Extended Apple Intelligence学習用全ページブロック User-agent: ClaudeBot Claude公式Bot全ページブロック User-agent: Claude-Web Claude Webブラウジング全ページブロック User-agent: Claude-SearchBot Claude検索機能全ページブロック User-agent: Claude-User Claudeユーザーのブラウジング機能全ページブロック User-agent: PerplexityBot Perplexity公式Bot全ページブロック User-agent: Perplexity-ai Perplexity AI全ページブロック User-agent: Perplexity-User Perplexityユーザーのブラウジング機能全ページブロック User-agent: Bytespider ByteDance(TikTok)AI学習用全ページブロック User-agent: Diffbot Diffbot構造化データ抽出全ページブロック User-agent: FacebookBot FacebookBotコンテンツ収集全ページブロック User-agent: OAI-SearchBot OpenAI検索補助Bot全ページブロック User-agent: MJ12bot MajesticSEOツール用全ページブロック User-agent: PiplBot Pipl人物検索エンジン全ページブロック User-agent: Meta-ExternalAgent Meta外部リンク情報収集全ページブロック
User-agent: Timpibot Timpi検索エンジン全ページブロック

【機能1】記事の「中身だけ」を綺麗に抽出
Webサイトには広告、メニュー、関連記事リンクなど、記事本文以外の要素がたくさんあります。newspaper4kは、独自のアルゴリズムでこれらを自動で除外し、 記事の本文だけを綺麗に抽出 してくれます。
抽出できる情報:
-
タイトル
-
本文テキスト
-
著者名
-
公開日時
-
トップ画像
-
記事内の全画像
-
動画のURL
-
メタデータ(description、keywordsなど)
対応言語:
80以上の言語に対応しており、日本語、英語、中国語、スペイン語など、多言語のニュースサイトから情報を抽出できます。言語は自動検出されるため、特別な設定は不要です。
【機能2】記事からキーワードを抽出&自動要約
newspaper4kの強力な機能の一つが、 自然言語処理(NLP) による自動分析と説明されています。
しかし、この機能は日本語には対応していませんでした。
自然言語処理はあくまでルールベースの処理であり、生成AIの処理とは異なることに注意は必要です(単語が何回出てくるかをカウントする仕組みなど)。
【機能3】サイト全体からの一括収集に対応
記事単体だけでなく、指定したドメインに記載されている全ての記事を一括収集することも可能ということです。
【機能4】画像も一緒に取得できる
記事に使われている画像を取得することができます。
newspaper4kの導入と基本操作
インストール

関数は主に2種類
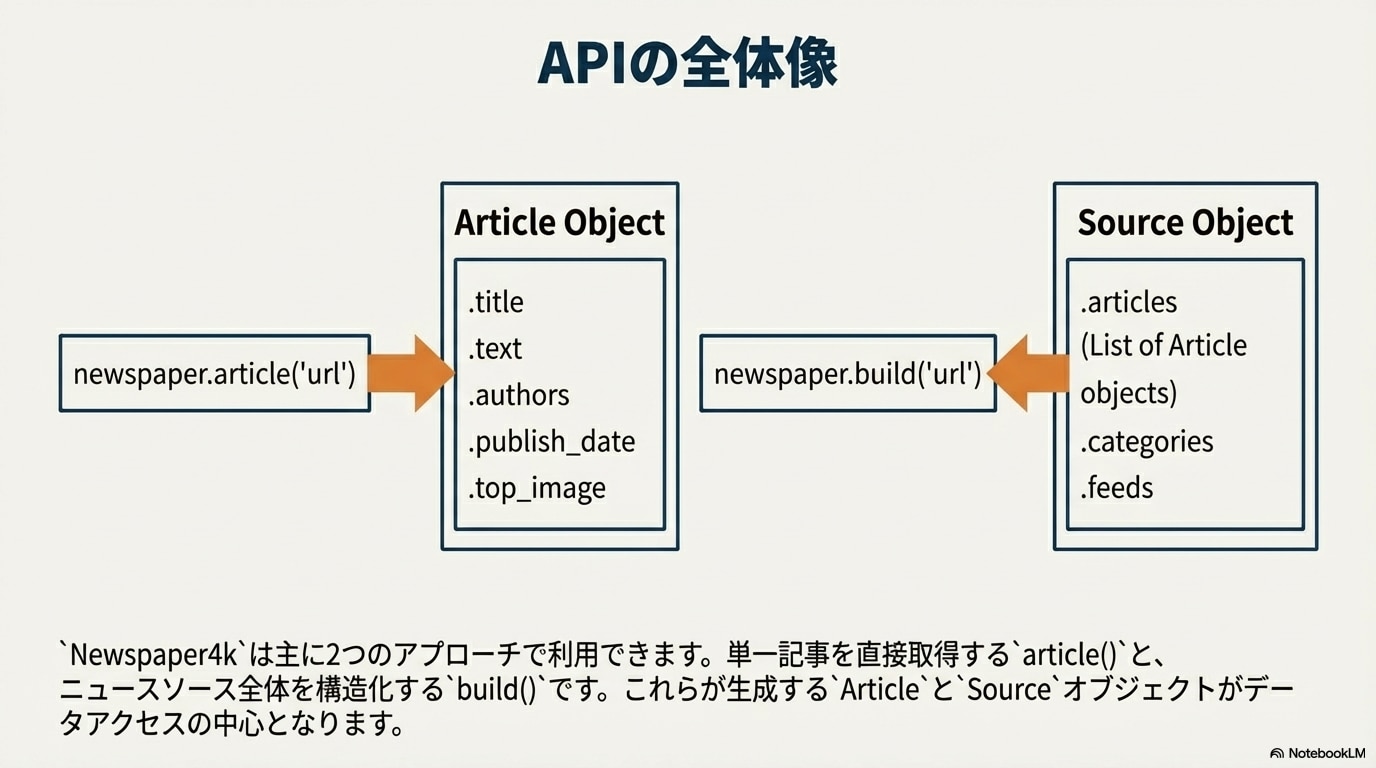
【実践1】ITmediaのニュースを取得する
ここからは実際にnewspaper4kを使ってニュースデータを取得してみます。
対象はこちらの記事を使ってみます。
生成AIの日常使用率、日本は51%で世界平均を大きく下回る newspaper.articlel()でURLを入力して実行します。

このような形でタイトルや本文、公開日などが取得できました。
筆者、キーワード、要約は空欄となっています。
キーワードや要約の部分はNLPの機能となり、日本語には対応していないようです。
【実践例2】サイトから全記事を取得する
newspaper4kの独自機能として、ドメイン配下にある全記事を取得する機能も持ち合わせているようです。
Source()でドメインを入れると以下のように出力してくれました。
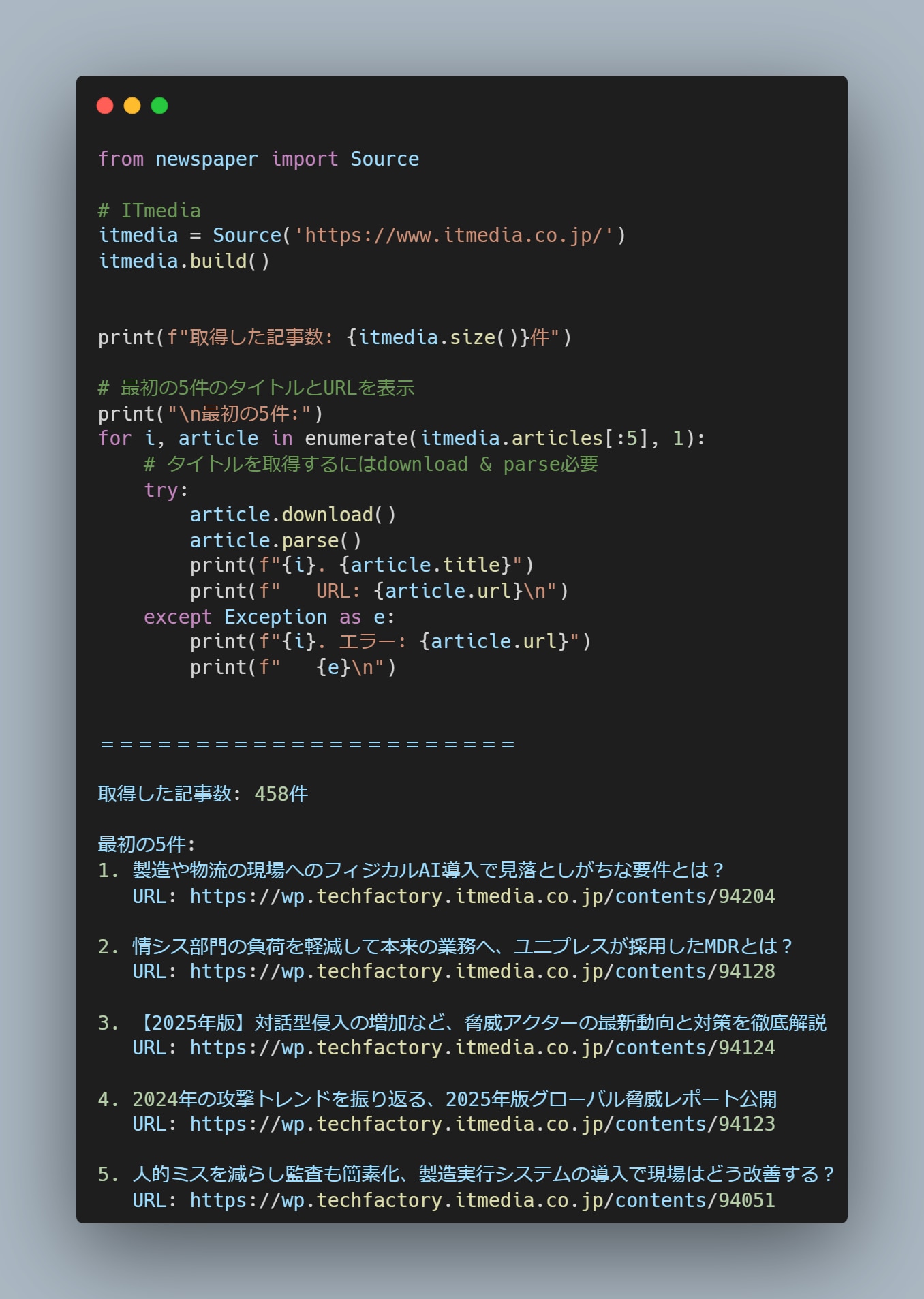
458件の記事が取得できました。
newspaper4kのメリット
✅ メリット1:使いやすさ
たった1行で記事取得:
article = newspaper.article('https://example.com/news')
これだけで、ダウンロード、解析、NLP処理まで全て完了します(日本語未対応)。
豊富なドキュメント:
-
コード例が充実

学習コストが低い:
-
Pythonの基礎知識があれば使える
-
BeautifulSoupやScrapyのような複雑な設定不要
-
すぐに実用的な結果が得られる
✅ メリット2:多言語対応で世界中のニュースを収集

80以上の言語に対応:
-
日本語、英語、中国語、韓国語、スペイン語、フランス語、ドイツ語...
-
言語は自動検出されるため、設定不要
-
バージョン0.9.3で40以上の新言語が追加
実例:多言語記事の収集
# 日本語記事 article_ja = newspaper.article('https://www.itmedia.co.jp/news/...') # 英語記事 article_en = newspaper.article('https://techcrunch.com/...') # 両方とも自動で言語を検出して処理
グローバルな情報収集が簡単に実現できます。
✅ メリット3:AIツールとの連携が簡単
newspaper4kは、ChatGPTやClaude、その他のAIツールとの連携に最適です。
LangChainの公式サポート:
LangChainという人気のAI開発フレームワークで、公式にサポートされています。
from langchain_community.document_loaders import NewsURLLoader # NewsURLLoaderは内部でnewspaper3k/4kを使用 loader = NewsURLLoader( urls=["https://www.itmedia.co.jp/news/..."], nlp=True # キーワード・要約も取得 ) documents = loader.load()

LangChain Reference Docs
Unified API reference documentation for LangChain, LangGraph, DeepAgents, LangSmith, and Integrations.
api.python.langchain.com
RAG(検索拡張生成)システムとの親和性:
-
記事データを自動で構造化
-
メタデータ(タイトル、著者、日付、キーワード)を付与
-
ベクトルデータベースへの保存が容易
-
ChatGPTに最新ニュースを教えるシステムが簡単に構築可能
✅ メリット4:オープンソースで無料
ライセンス:
-
MIT / Apache-2.0 の二重ライセンス
-
商用利用可能
-
無料で使い放題
-
ソースコードの改変・再配布も自由
コスト面のメリット:
-
有料のニュースAPI不要
-
サーバー費用のみ(自分のPCで実行可能)
-
大量のニュース記事を低コストで収集
✅ メリット5:活発な開発コミュニティ
継続的なアップデート:
-
2023年10月のフォーク以降、定期的にリリース
-
最新版は2025年11月(v0.9.4)
-
バグ修正と新機能追加が活発
コミュニティサポート:
-
GitHubのissueで質問・報告が可能
-
400以上のissueから180まで削減(継続対応中)
-
開発者が積極的に対応
パフォーマンス改善:
-
F1スコア: 0.9100 → 0.9460(v0.9.3で向上)
-
解析精度が継続的に改善
newspaper4kのデメリット
良い面ばかりではありません。デメリットも正直にお伝えします。
❌ デメリット1:動的コンテンツには追加ツールが必要
問題:
JavaScriptで動的に生成されるコンテンツは、newspaper4k単体では取得できません。
動的コンテンツの例:
-
無限スクロール:Twitter/X、Medium、Instagramなど
-
「もっと見る」ボタン:クリックで記事が追加表示
-
SPA(Single Page Application):Gmail、一部のBBCニュースなど
-
遅延読み込み:スクロールで画像や記事が読み込まれる
なぜ取得できない?
newspaper4kは静的なHTMLを解析します。最初のHTMLにコンテンツが含まれていない場合、抽出できません。
対処方法:PlaywrightやSeleniumと併用
from playwright.sync_api import sync_playwright import newspaper # Playwrightでページを開く with sync_playwright() as p: browser = p.chromium.launch() page = browser.new_page() page.goto('https://dynamic-site.com/article') # スクロールして動的コンテンツを読み込む for _ in range(5): page.keyboard.press('PageDown') page.wait_for_timeout(1000) # レンダリング後のHTMLを取得 html = page.content() browser.close() # newspaper4kで解析 article = newspaper.Article('') article.set_html(html) article.parse()
追加の学習コストと複雑性が発生 しますが、組み合わせれば解決可能です。
❌ デメリット2:有料記事には対応していない
問題:
会員限定コンテンツや有料記事は取得できません。
対応していないケース:
-
日経電子版の有料会員限定記事
-
NewsPicks Pro限定記事
-
その他サブスクリプション型メディア
理由:
ログイン認証やトークンが必要なサイトには、標準機能では対応していません。
代替アプローチ:
-
Playwrightで認証フローを自動化(技術的には可能だが複雑)
-
APIが提供されていればそちらを利用
-
無料公開部分のみを対象にする
❌ デメリット3:大量アクセスでIPブロックのリスク
問題:
同一サイトに短時間で大量アクセスすると、IPアドレスがブロックされる可能性があります。
リスク要因:
-
レート制限(rate limiting)
-
サーバー側の負荷対策
-
スパム判定
対策:
import time # アクセス間隔を2秒以上空ける for url in urls: article = newspaper.article(url) time.sleep(2) # 2秒待機
推奨事項:
-
最低1秒、推奨2秒以上の間隔
-
User-Agentを適切に設定
-
プロキシのローテーション(大量収集時)
-
並列処理のスレッド数を制限(3〜5スレッド程度)
❌ デメリット4:サイトによって精度にバラつき
問題:
サイトの構造によっては、抽出精度が低下することがあります。
精度が落ちるケース:
-
特殊なレイアウトのサイト
-
コードを含む技術記事(順序が乱れる可能性)
-
広告が多いサイト
-
複雑なHTML構造
パフォーマンス指標:
-
Scraperhubベンチマーク: F1スコア 0.9460(v0.9.3)
-
つまり、約94.6%の精度
-
主要なニュースサイトでは高精度
対処法:
-
抽出結果を確認して、必要に応じて後処理
-
特定サイト用のカスタムパーサーを作成
-
複数ツールを併用(BeautifulSoupでの補完など)
【まとめ】ニュース分析にnewspaper4kは使えるのか?
結論から言うと、
・コストがかかっても良いなら Firecrawl 一択
・無料ならあり(だが積極的に使う必要性は疑問)
といった感じでしょうか。
スクレイピングツール「 Firecrawl」は、Bot対策などが強力であり、newspaper4kで取れないページも簡単に取得できます。
開発力・技術力も桁違いで、LLMを使ったスクレイピング機能なども追加されており、ニュースデータ取得のベストプラクティスの一つとして、コストを考慮しないのであればFirecrawl一択といっても良いでしょう。
Firecrawlはドメイン直下にあるデータを全てmdファイルで落とすこともできます。
例えば、
-
Firecrawlで特定のWebサイトの記事一覧をデータ取得
-
Notebooklmに突っ込む
-
動画にして理解を深める
とすれば撃速で理解しやすい動画が作れます。例↓
以上、newspaper4kの解説でした。
LLMの登場でニュースを取得・分析するビジjネス的可能性が更に広がりました。
効率的にニュースデータを整理、分類、活用し、さらなるビジネスの発展に繋げていきましょう。
当社では、企業のDXの課題解決として生成AI導入支援を行っています。
ご相談等フォームよりお気軽にご相談ください。