RealtimeAPIとは
OpenAIから新たにRealtimeAPIが公開されました。最近のOpenAIのデモでも使われたもので、ChatGPTのようなAIとの会話をタイムラグを感じさせることなくリアルタイムですることができます。
既にChatGPTのアプリ版には搭載されていますが、今回これがAPIとして公開されました。
Function Callも使用可能
RealtimeAPIは他の生成AIのAPIと同様、外部関数が利用可能なFunction Call機能も搭載されています。
そして早速、ノーコードAIアプリケーション「Dify」のクローリングツールとしても有名なツール「Firecrawl」により、スクレイピング技術と融合させたデモが公開されました。
— @nickscamara\_ (@nickscamara_) 午後4:42 · 2024年10月4日[Using OpenAI's Realtime API and Firecrawl to Talk with Any WebsiteBuild a real-time conversational agent that interacts with any website using OpenAI's Realtime API and Firecrawl.Firecrawl](https://www.firecrawl.dev/blog/How-to-Talk-with-Any-Website-Using-OpenAIs-Realtime-API-and-Firecrawl)
ブログにもサンプルコードや利用方法などが公開されているため、今回はこちらを日本語で実装してみたいと思います。
実演:RealtimeAPIでYahooニュースを探索してみる
実際の実行状況を以下にアップロードしました。
このようにYahooニュースも問題なくスクレイピングできており、ニュースの内容も解説してくれました。
AIとの会話の中で、スクレイピングツール「Firecrawl」をFunction callとして使うことで、ニュースを取得するもので、映像に出てくるニュースの画像は、スクレイピングプロセスの一貫としてキャプチャー(静止画像)を取って表示させたものになります。
機能は現在、指定した単一ページをスクレイピングするscrape_dataと、単一URLからURLを抽出しキーワードで探すmap_websiteの2つが公開されています。
scrape_data
client.addTool(
{
name: 'scrape_data',
description: 'Goes to or scrapes data from a given URL using Firecrawl.',
parameters: {
type: 'object',
properties: {
url: {
type: 'string',
description: 'URL to scrape data from',
},
},
required: ['url'],
},
},
async ({ url }: { url: string }) => {
const firecrawl = new FirecrawlApp({
apiKey: process.env.FIRECRAWL_API_KEY || '',
});
const data = await firecrawl.scrapeUrl(url, {
formats: ['markdown', 'screenshot'],
});
if (!data.success) {
return 'Failed to scrape data from the given URL.';
}
setScreenshot(data.screenshot || '');
return data.markdown;
}
);
map_website
client.addTool(
{
name: 'map_website',
description: 'Searches a website for pages containing specific keywords using Firecrawl.',
parameters: {
type: 'object',
properties: {
url: {
type: 'string',
description: 'URL of the website to search',
},
search: {
type: 'string',
description: 'Keywords to search for (2-3 max)',
},
},
required: ['url', 'search'],
},
},
async ({ url, search }: { url: string; search: string }) => {
const firecrawl = new FirecrawlApp({
apiKey: process.env.FIRECRAWL_API_KEY || '',
});
const mapData = await firecrawl.mapUrl(url, { search });
if (!mapData.success || !mapData.links?.length) {
return 'No pages found with the specified keywords.';
}
const topLink = mapData.links[0];
const scrapeData = await firecrawl.scrapeUrl(topLink, {
formats: ['markdown', 'screenshot'],
});
if (!scrapeData.success) {
return 'Failed to retrieve data from the found page.';
}
setScreenshot(scrapeData.screenshot || '');
return scrapeData.markdown;
}
);
他のFunction Callと同様、toolに設定するだけ追加実装が可能なため、例えば SEOツールのahrefsをWebサイトを見ながらAIに音声で指示 したり、 音声でXの投稿文を作らせ投稿させる こともできます。
RealtimeAPIは非常に高額
ちなみにこのAPIは音声データを扱うだけあって、他のAPIと比べ非常に割高です。
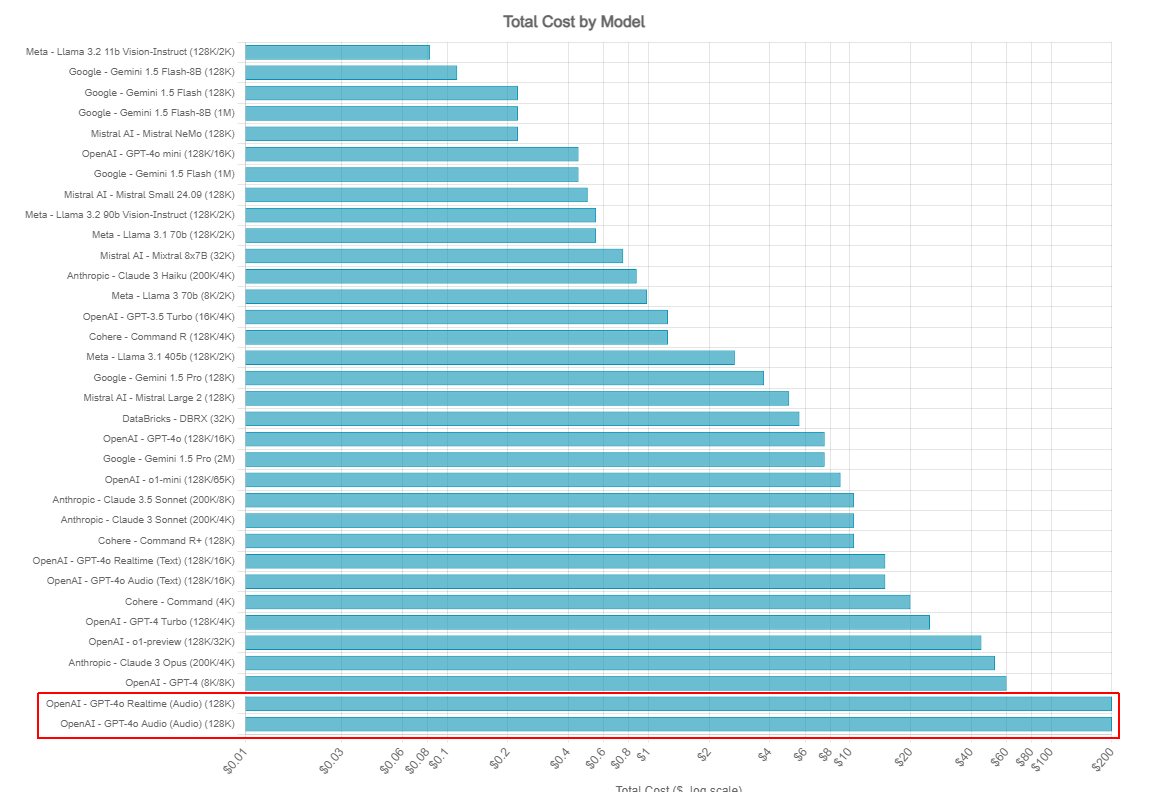
同じトークン数でもGPT-4o-miniの4倍以上する上に、音声データなのでデータ量そのものがテキストと比べ圧倒的に多いです。
この実験の動画だけでも何回か繰り返していたらあっという間に何十ドルもかかってしまいました。スクレイピングする際は、Firecrawlからの戻りデータ量をある程度制限してLLMに渡したほうが良いでしょう。
コストは時間で解消されると思いますが、早く安くなってほしいものです。
AIが自発的に動くエージェントの時代は、情報消費は人からAIへ
生成AIはFunction Callという外部機能を使うことにより、人間が行う様々な行動の代替が可能となります。
そして生成AIは、それらの行動を自発的に考えて行うことが可能です。
今後はこれまで対人相手に行っていたマーケティングや広報活動も、今後は自発的に行動するAIを対象にする時代が、そう遠くない未来にやってくるかもしれません。
寝ている間にAIがクローリングして情報収集する時代に

「人間は平等に24時間しか持っていない」と言われた時代は過去の時代になるかもしれません。
映画やドラマ、小説、ニュースなどのコンテンツは、自分のことをよく学習させたAIに”食わせ”さえすれば、面白かったかつまらなかったか、感動するかしないかは判断がつくようになるでしょう。
情報収集は寝ている間にAIが行い、厳選した情報だけを朝に読むということも可能となるでしょう。
そうした時代に入ると、SEOなどが大きな一つの産業となっている中で、「対アルゴリズム」という考えが重要となるかもしれません。
雑誌は紙からAPIへ?
雑誌メディアの衰退が激しいですが、紙媒体が衰退している理由はその流通における産業構造にあり、良いコンテンツが欲しいと思うニーズは今後も減らないでしょう。
2024年4-6月期 雑誌印刷部数を分析する2024年4-6月期の雑誌印刷部数を分析します。広報・PR支援の株式会社ガーオン
良いコンテンツを取材して集め、キュレーションするというメディアの価値そのものは、生成AI後の世界でも依然として強いのではないでしょか。
そうした時代には、情報コンテンツをAPIとして発信することが主流になるかもしれません。APIであればYahooニュースのようにスクレイピングせずに、必要な情報だけを取得することが可能です
以上、OpenAIが発表した、RealtimeAPIの解説でした。