AI 機械学習
本日、朝日新聞デジタルにTwitterの分析記事が掲載されていました。
当ブログではこれまでにTwitterやヤフーニュースなどの口コミ分析として、AmazonやGoogleのAutoMLを使った自然言語処理を試してみました。
Amazonの人工知能を使ってSNS等の口コミを感情分析する方法
「10万再給付ない」麻生大臣発言で大炎上した2万超のヤフトピコメントをAI解析する
今回は、上記朝日新聞の記事にも使われている「ML-Ask」という感情分析モデルを実際に使ってみて検証していきたいと思います。
ML-Askとは
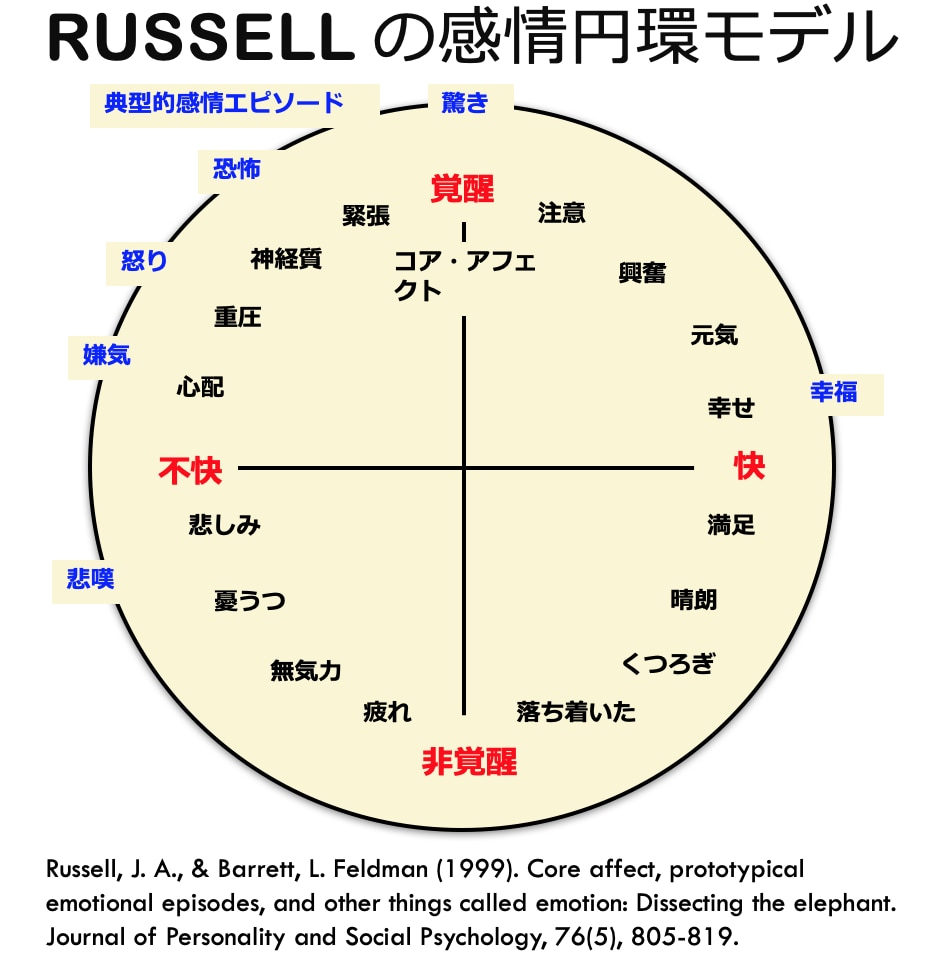
ML-Askは、 感情表現辞典 やラッセルの2次元感情モデルなどを使い、入力したテキストデータから「喜・怒・昂・哀・好・怖・安・厭・驚・恥」の10種類の感情を抽出するというモデルということです。
Michal Ptaszynski / Research
This is a homepage of Michal Ptaszynski
arakilab.media.eng.hokudai.ac.jp
Pythonの無料ライブラリの一つにもなっており、下記3行のシンプルなコードで実行することが可能です。
$pip install pymlask
from mlask import MLAsk
emotion_analyzer = MLAsk()
emotion_analyzer.analyze("text")
朝日新聞の記事では、2回発令された非常事態宣言の前後2週間を対象に全量ツイートをML-Askで分析したそうです(実際に分析したのはJX通信社)。
朝日新聞の記事では8万件のデータを対象にしたそうですが、今回は試しに同時期にランダムで抽出した1,000件のTwitterデータをそれぞれML-Askで分析してみたいと思います。
朝日新聞の記事ではリツイートデータが含まれている可能性が高いですが、今回はリツイートデータやメンションデータは全て除いた形で抽出しています。
ツイートを分析
まず対象ワードを含む全体のTwitter投稿数を確認してみます。
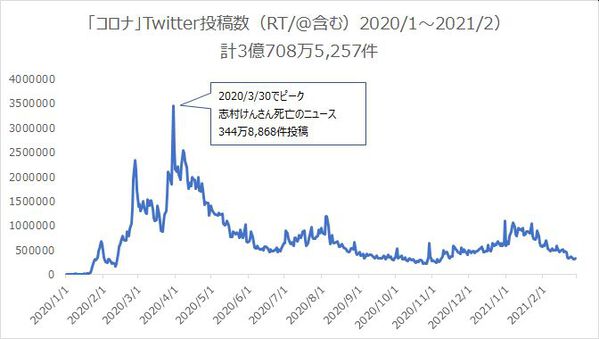
対象ワードの全体の投稿数は、志村けんさんのニュースが流れた2020/3/30にピークを迎え、その後小ピークを2020/8と2021/1頃に確認でき、全体的には減少傾向にあります。
ML-Askで感情を抽出
続いて朝日新聞の記事にもある、2回の非常事態宣言の前後2週間のTwitterデータをそれぞれML-Askで分析した結果が下記です。
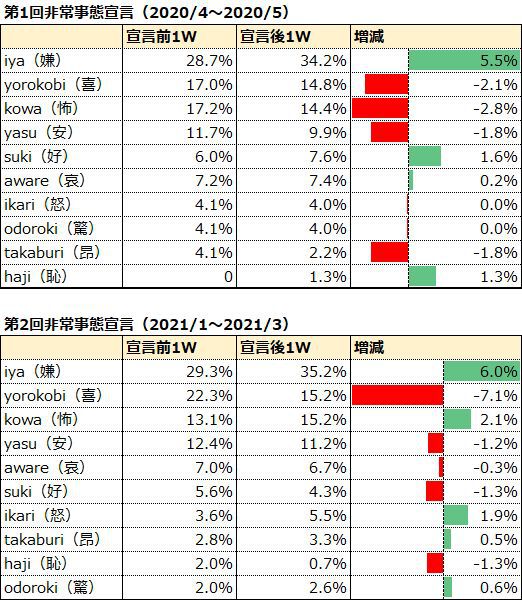
こちらをグラフ化したのが下記です。
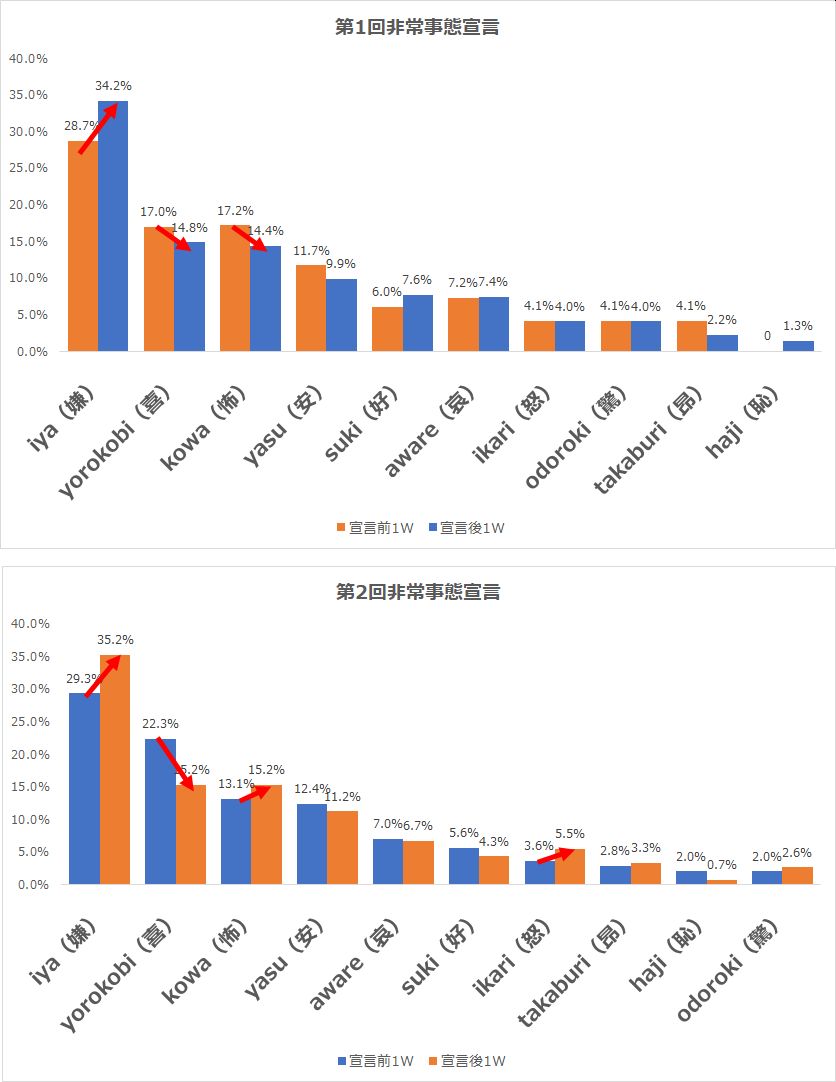
1回目の非常事態宣言では、宣言後で「嫌」が増加し、「喜」「怖」が減少傾向にあります。
2回目の非常事態宣言では、こちらも宣言語で「嫌」が増加し「喜」が減少する一方、「怖」は増加する傾向が見て取れます。また1回目と異なり「怒」が増えているのも特徴です。
朝日新聞の記事では、
1回目の宣言時は、宣言前より「哀」「怖」の割合が約2~4ポイント減った一方、安心といった感情を含む「安」や「喜」が約2ポイント増えていた。(中略)2回目の宣言後は、宣言前に比べて「厭」や「怖」の感情に分類されたツイートの割合が約2~3ポイント増え、逆に「安」「喜」などのポジティブな感情が約1~5ポイント減っていた。
という傾向が見られたそうですが、今回何故か記事とは少し異なる結果となりました。
原因としては「サンプル数が異なる」「朝日新聞はRTデータを含んでいる」などが挙げられるかもしれませんが、実際に分析してみるとそもそも論として、そもそも今回の対象ワードを分析基準となるワードにして共起語を見つける事自体に意味があるのかという疑問も浮き上がりました。(そもそもそんな毎回対象ワードを入れてつぶやかないですよね。。)
実際に使えるAIはどれだ!?モデル別に比較
さてここからは感情分析モデルをそれぞれ実際に比較していきたいと思います。
比較するモデルは今回使った「ML-Ask」、GoogleのAutoMLの一つである「Google Natural Language API」、AmazonのAutoMLである「Amazon Comprehend」の3つです。
対象は「怖くて相撲を引退する」というニュースで話題となった、琴貫鐵(ことかんてつ)さんのツイートを使わせていただきます。
今日を持って 引退することになりました。 このコロナの中、 両国まで行き相撲を取るのは さすがに怖いので 休場したいと佐渡ケ嶽親方に伝え 協会に連絡してもらった結果 協会からコロナが怖いで 休場は無理だと言われたらしく 出るか辞めるかの 選択肢しか無く 自分の体が大事なので
— 柳原大将(元琴貫鐵大将) (@miyakuradaisuke) 午前1:49 · 2021年1月9日
ちなみに琴貫鐵(ことかんてつ)さんは、実際には以前に心臓手術をしており、疾病リスクが高いため休場を望んだそうですが、相撲協会が休場を許さずに結局引退することになった、という経緯があったそうです。
この投稿文は人間が見ると、感染への「恐怖・不安」と相撲協会への「怒り」が感じ取れます。各種AIはこうした文脈理解もなく、どのようなアウトプットを出せるのでしょうか。
ml-maskで分析すると
| 感情 | ネガポジ | アクティブさ |
| kowa(怖い) | NEGATIVE | ACTIVE |
解説によると「ネガティブかつアクティブ」は「怒り」だそうなので、上手く分析できているようです。
Google Natural Language APIで分析すると
| センチメントスコア(-1.0~+1.0)全体的感情 | マグニチュード(感情的な度合い) |
| -0.30000001192092896 | 0.699999988079071 |
センチメントスコアが-0.3なのでネガティブ、かつ感情の度合いを表すマグニチュードが0.69と比較的高いため、「ネガティブでかつ感情的」であるという結果となりました。
ただし、Google Natural Language APIは具体的な感情は出力されないため、ネガティブが「怒り」なのか「悲しみ」なのか「恐怖」なのかは分からないのがネックです。
Amazon Comprehendで分析すると
| ニュートラル | ポジティブ | ネガティブ | 混合 |
| 39% | 0% | 60% | 0% |
Amazonの自然言語処理であるAmazon Comprehendは、シンプルにネガポジの確率を全体を100%としたソフトマックス関数でそれぞれ出力してくれます。今回はネガティブな可能性が60%、中立な可能性が39%という結果となりました。
ML-Askの欠点
ML-Askはこのように具体的な喜怒哀楽の感情を抽出してくれるので、他の自然言語処理AIよりも便利な気もしますが、辞書型のデータベースを活用しているため、テキストデータに分析対象の感情が入っていないとそもそも分類できず、全てのテキストデータには対応できないという大きな欠点があることが分かりました。
具体的には今回のTwitterの投稿データだと、全体の30~35%しか分類してくれません。
朝日新聞の記事の8万件のデータを使ったという表記がありましたが、恐らく実際に分類できたのは2.5万件ほどだったのではないでしょうか。
結論
- 全体の傾向推移を見るにはML-Askは便利
- ネガティブ度合いやポジティブ度合いなど数字では出せない
- Twitterデータだと3割ほどしか分類できない
- 漏れなく全てを分類するにはGoogleやAmazonなどのAIを使ったほうが良い
- 単純分類であればAmazon Comprehendが楽(Googleは閾値設定やら解釈が面倒)
以上、ML-Askの解説でした。ML-Askを使ったウイルスとツイートデータの関係性分析は下記論文などにも詳しく載っているのでご参考まで。
参考) www.jstage.jst.go.jp/…35/4/35_F-K45/_pdf
▼合わせて読みたい