2024/7/18更新追記:日本新聞協会が「検索連動生成AIは著作権侵害の可能性がある」という声明を2024年7月17日に発表しました。
www.pressnet.or.jp/…40717_15523.html// これは 著作権法47条5「電子計算機による情報処理及びその結果の提供に付随する軽微利用等に関する権利制限」を焦点としたものです。
生成AIの法議論としては、「著作権法47条5(著作物の軽微利用=検索結果に著作物を利用する等)」と、当ブログで解説している「 30条の4(享受と情報解析=RAG)」の 2種類の争点がある ようです。
最新動画: 2024/8/9開催:文化庁「令和6年度著作権セミナー「AIと著作権Ⅱ」 」最新セミナー
AI3行要約:
- 生成AIによる著作権侵害の判断基準:AI生成物が既存の著作物と類似性および依拠性がある場合、権利制限規定が適用されない限り著作権侵害となる。
- AI開発学習段階での著作権法適用:著作物を学習データとして使用する場合、著作権法第30条の4により原則として著作権者の許諾は不要だが、例外も存在する。
- 著作権侵害の責任主体:AI利用による著作権侵害の場合、主にAI利用者が責任を負うが、AI開発者やAI提供者も責任を負う可能性がある。
AI1行要約:AIと著作権の関係については、まだ明確な結論が出ておらず、法的解釈や規制は今後も変化する可能性が高い。
生成AIの独自データ活用技術であるRAG(Retrieval Augmented Generation)は、企業の業務効率化や情報精度向上にとっても非常に重要な技術の一つです。
広報PR・マーケティング領域でも、過去のニュースを参考にPR企画の立案や壁打ちを行なったり、メディアリストからアプローチすべきジャーナリストをピックアップしたりと、様々な活用の展開方法が期待できます。
一方で、RAGには著作権の問題も浮上しています。この記事では、RAGの仕組みと利点、そして非常に複雑で分かりにくい著作権との関係性について、なるべく分かりやすく解説します。
RAG(Retrieval Augmented Generation) とは
RAG(検索拡張生成)は、検索AIと生成AIモデルを統合した技術で、質問応答や文章生成において3つの主要なステップで動作します。
- 事前のテキスト情報などを数値に変換し、データベースに保存しておく
- ユーザーからの質問を数値化して、データベースから似ているデータを探す
- 探し出したデータベースの結果を”カンニング”させながら、LLMに回答させる
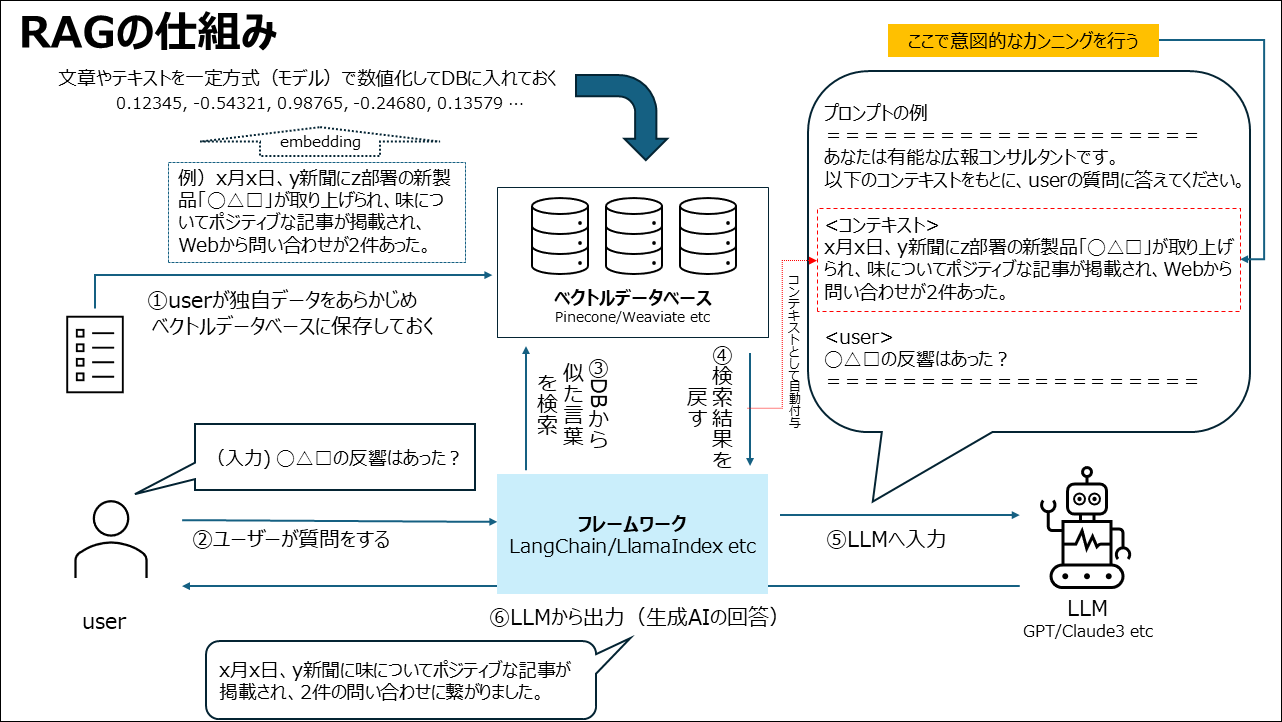
ポイントはカンニングさせるということです。カンニングなので、より正しいカンニングペーパーを使わせることが重要となります。
図にすると上記のようなフローとなります。
生成AIの世界では、単語だけでなく、文章やまとまった一定の長さのテキスト(チャンク)を数値化させることができます。
数値があれば方向性(ベクトル)を出せるということで、近い・遠い、角度が狭い、広いといった表現ができ、この近似値が近いものを探してきて、生成AIの回答の際に、カンニング的に与えて、回答されることで精度を上げる、という流れです。
チャンクとオーバーラップとは
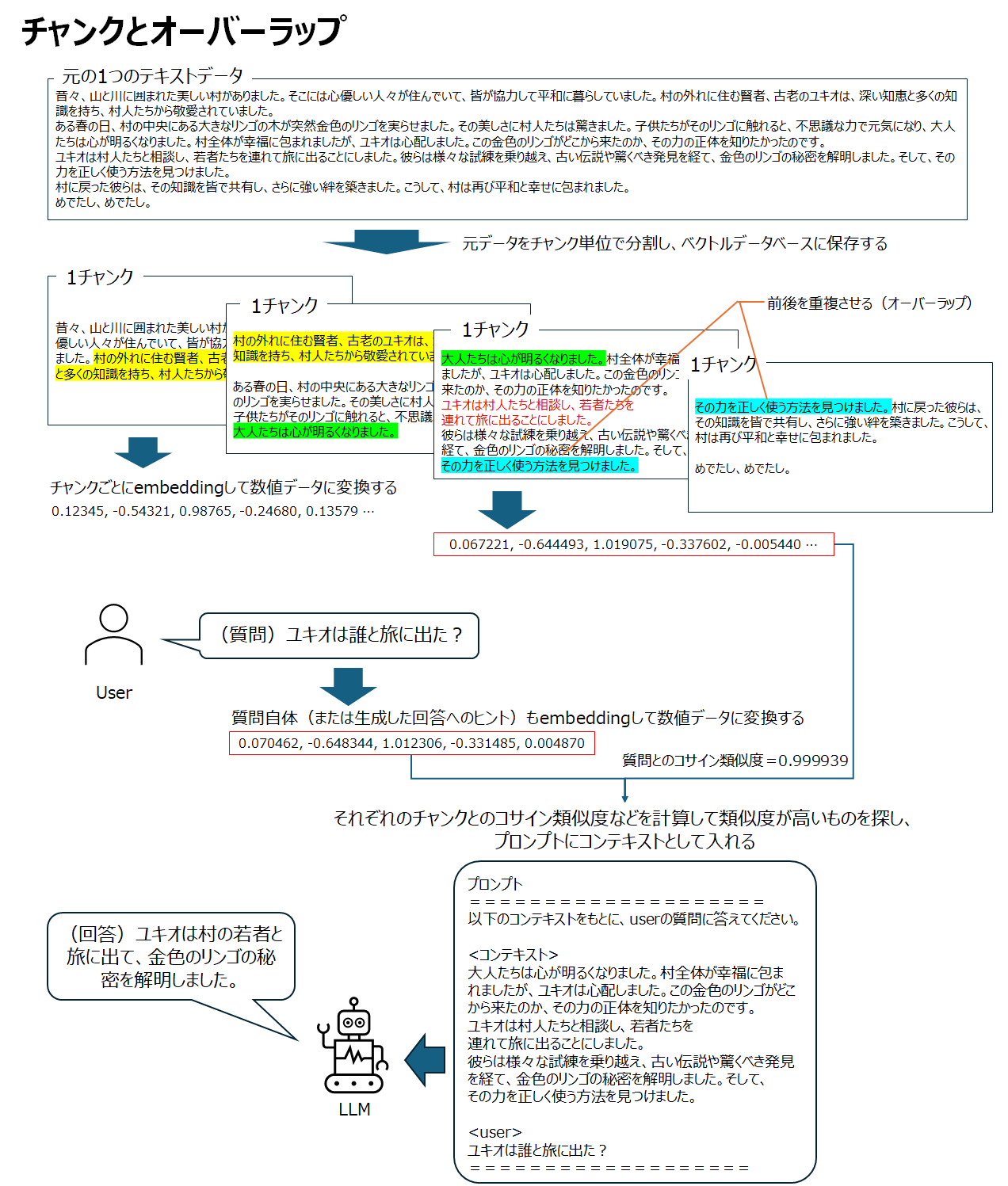
(補足)このカンニングペーパー一つ一つのことを「チャンク」と呼びます。チャンクはトークン(Token/日本語では「単語」に近い)単位でカウントされ、Difyではディフォルトが1チャンク=500 Tokenとなります。つまり1カンニングペーパーを500ワードでまとめて、それを何枚もデータベースに入れ、検索して取り出して使うというイメージです。
カンニングペーパー(チャンク)には検索用として、意図的に重複箇所を盛り込みます。これを「オーバーラップ」といいます。
ちなみにマイクロソフトの研究では、1チャンク約500トークン、オーバーラップを前後25%で行なった際の精度が最も良かったと報告されています。
こうした文書のデータ化を自動的に行なってくれるのが Dify であり、Difyを使用すれば事前知識などなくこうしたRAG機能を実装することが可能です。
【Dify活用】生成AIで広報リサーチ業務を行う方法ノーコードLLM開発ツールDifyを活用して、効率的にニュースのリサーチを行う方法を解説します。広報・PR支援の株式会社ガーオン
生成AIと著作権の法的課題
RAGは非常に強力なツールとなりますが、忘れてはならないのが著作権の問題です。
生成AIの急速な発展に伴い、著作権法の適用範囲と解釈に関する新たな課題が浮上し、クリエイターの権利保護とAI技術の発展のバランスを取る新たな法的枠組みの構築が急務となっています。
日本国内では文化庁が音頭を取り、AI開発・学習段階での著作物利用について、有識者と議論を続けているようです。
特に議論となっており、AIと著作権で必ず出てくるのが、 著作権法30条の4と呼ばれる箇所の「著作物をAIに学習・推論させてよいのか」 というポイントです。
著作権法30条の4について
この「著作権法30条の4」を抜粋してみます。
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。 ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合 二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。 第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
第30条の4第2号によれば、AI開発等の「情報解析」に必要な範囲であれば、著作物を自由に利用することが認められています。
ここが日本が生成AI学習天国と呼ばれる一因でもあり、各国が生成AIの拠点を日本に置こうとする要因ともされているようです。
参考) 文化庁「AI と著作権に関する考え方について」令和6年3月15日
参考) 文化庁「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方」令和元年10月24日
第30条の4のポイントは「享受」という言葉です。ここまでくると法律用語遊びのようで、頭が痛くなってきますが、享受に関しても以下の説明が記載されています。
「享受」とは、一般的には「精神的にすぐれたものや物質上の利益などを、受け入れ味わいたのしむこと」(新村出編(20172017)広辞苑(第七版)岩波書店762 頁)を意味することとされており、ある行為が法第30 条の4に規定する「著作物に表現された思想又は感情」の「享受」を目的とする行為に該当するか否かは、同条の立法趣旨及び「享受」の一般的な語義を踏まえ、著作物等の視聴等を通じて、視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為であるか否かという観点から判断されることとなるものと考えられる。
ここまでをかなり雑にまとめてみると以下の内容となります(間違っていたら適宜修正して更新します)。
- 生成AIの著作権問題は「学習(膨大なテキストを学習させる)」と「推論(学習させたモデルに入力と出力をさせる)」に大きく分かれる
- 生成AIにおいての情報取得には「享受(表現を楽しむ)」と「情報分析」の2つの要素に分けることができる
- 「享受(表現を楽しむ) 」目的であれば著作権に違反するが、「情報分析」であれば著作権には違反しない(第30条の4第2号適応)※ただし著作権者の利益を不当に害する場合には違反
記事や番組データなど第三者著作物を利用したRAGは合法か
ここまででもかなりの分量となりましたが、次にポイントとなるのが、 「『享受』目的でなく、『情報分析』にあたるが、著作権者の利益を不当に害している場合」とは一体どんなシチュエーションなのか ということです。
広報やPR活動におけるRAGの活用としては、過去の記事やニュースデータ、メディア等のリスト、自社のプレスリリースや掲載情報などが最初に考えられるでしょう。
ここで特に調べておきたいのは、著作権で守られているニュース記事を、生成AIのRAGデータとして活用して問題ないのか、という点です。
クローズアップ現代を学習したAIはPRプランナーの夢を見るか
例えば、NHK「クローズアップ現代」のWEBサイトには、過去の膨大な放送データがテキスト化されて保存されています。
このWebサイトは一般公開されており、誰でも自由に見ることができます。 もちろんNHKサイドとしても、番組内容は著作権に守られており、”インターネットで流す”ことを禁じています。
現在、NHKでは、利用者がテレビやラジオの番組の画面や音声を取り込んで インターネットに利用すること については、番組に関係するさまざまの権利者の理解を得られる状況にないこと、肖像権等の問題があることなどの事情から、お断りしています。
NHKオンライン|放送番組と著作権
www.nhk.or.jp
ではこのデータを”インターネットに流す”のではなく、RAGとして活用し、自社の広報戦略に活用することは合法なのでしょうか。それとも違法なのでしょうか。
データベースと著作権
「AI と著作権に関する考え方について」では、以下のような記載が確認できます。
(ウ)情報解析に活用できる形で整理したデータベースの著作物の例について26
○ 上記(ア)のとおり、本ただし書への該当性は諸般の事情を総合的に考慮して検討することが必要と考えられるが、本ただし書に該当すると考えられる例としては、 「基本的な考え方」(9頁)において、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為」が既に示されている 27。 ○ この点に関して、上記の例で示されている「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」としては、 DVD 等の記録媒体に記録して提供されるもののみならず、インターネット上でファイルのダウンロードを可能とすることや、データの取得を可能とするAPI(Application Programming Interface Interface)の提供などにより、オンラインでデータが提供されるものも含まれ得る と考えられる。 ○ また、「当該データベースを(…………)複製等する行為」に関しては、データベースの著作権は、データベースの全体ではなくその一部分のみが利用される場合であっても、当該一部分でも創作的表現部分が利用されれば、その部分についても及ぶ(前掲・加戸142
(「AI と著作権に関する考え方について」より )
上記で、既に示されているというのは、以下の内容を指しています。
問9 法第30 条の4ただし書の「…著作権者の利益を不当に害することとなる場合」に当たるか否かはどのように判断されるか。
法第30条の4ただし書では,「著作権者の利益を不当に害することとなる場合」には,権利制限が適用されないことを定めているところ,当該場合に該当するか否かは,同様のただし書を置いている他の権利制限規定(法第35条第1項等)と同様に,著作権者の著作物の利用市場と衝突するか,あるいは将来における著作物の潜在的市場を阻害するかという観点から判断されることになる。 具体的な判断は最終的に司法の場でなされるものであるが, 例えば,大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為は,当該データベースの販売に関する市場と衝突するものとして「著作権者の利益を不当に害することとなる場合」に該当するものと考えられる。
(「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方」より)
つまりポイントとしては、 「デジタルメディアやAPI等で提供されているデータ」が、「(前処理などで)整理されており」、かつ「販売されている」状況においては、「著作権者の利益を不当に害することとなる場合」に該当する(違反となる) ということを言っているようです。
この資料ではAPIに関してもかなり多く言及されており、以下のような記載も見られます。
これを踏まえると、例えば、インターネット上のウェブサイトで、ユーザーの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できる API が有償で提供されている場合において、当該API を有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為は、本ただし書に該当し、同条による権利制限の対象とはならない場合があり得る と考えられる28 29。
○ この点に関しては、本ただし書の適用範囲が明確となることに資するよう、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPIが有償で提供されていること等の情報が、このような有償提供を行う権利者から事業者等の関係者に対して提供されることにより、AI 開発事業者及びAI サービス提供事業者においてこれらの事情を適切に認識できるような状態が実現されることが望ましい。 他方で、AI 学習のための著作物の複製等を防止するための、機械可読な方法による技術的な措置としては、現時点において既に広く行われているものが見受けられる。こうした措置をとることについては、著作権法上、特段の制限は設けられておらず、権利者やウェブサイトの管理者の判断によって自由に行うことが可能である。 (例)ウェブサイト内のファイル robots.txt” への記述によって、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスを制限する措置 (例)ID ・パスワード等を用いた認証によって、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスを制限する措置
このような技術的な措置は、あるウェブサイト内に掲載されている多数のデータを集積して、情報解析に活用できる形で整理したデータベースの著作物として販売する際に、当該データベースの販売市場との競合を生じさせないために講じられていると評価し得る例がある(データベースの販売に伴う措置、又は販売の準備行為としての措置)30。
有料APIで提供している情報を、無償でスクレイピングするのは「著作権者の利益を不当に害することとなる場合 」に該当し、違法となりえるということを言っているようです。
robots.txtなどのチェックはマストに?
クローラーに対してどのような対策を取っているかが、著作権保有側の対応・態度・意向として重要になるような記載も見受けられます。
28 この点に関して、インターネット上のウェブサイトに掲載されたデータについては、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスが、後述するウェブサイト内のファイル robots.txt” への記述により制限されていない場合、「(大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が)販売されている場合」に該当しないことを推認させる要素となる ものと考えられる。もっとも、この点に関しては、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスが、 robots.txt” への記述により制限されていないという事情は、クローラによるAI 学習のための複製が著作権侵害となる場合に、当該複製を行う者の過失を否定する要素となるにとどまるとの意見もあった。
29 API により提供されているのが「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」に該当するか否か、及び、本ただし書に該当するか否かについては個別の事例に応じた検討が必要となるが、具体例としては、学術論文の出版社が論文データについて テキスト・データマイニング用ライセンス及びAPI を提供している事例や、新聞社が記事データについて同様のライセンス及びAPI を提供している事例等がある。 もっとも、テキスト・データマイニング用ライセンス及びAPI を提供しているとしても、当該APIが「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」に当たるとは限らないといった意見もあった。 30 このような、AI 学習のための著作物の複製等を防止する技術的な措置と、情報解析に活用できる形で整理したデータベースの著作物としての販売が併せて実施されている具体例としては、 The New York Times Times(米国)が自社記事を掲載するウェブサイトのrobots.txt においてAI 学習データ収集用クローラをブロックし、別途、テキスト・データマイニング用ライセンス及びAPI を提供している事例や、Financial Times 、TheGuardianGuardian(いずれも英国)が同様の取組を行っている事例、Axel Springer Springer(ドイツ)が傘下メディアの記事を掲載するウェブサイトのrobots.txt においてAI 学習データ収集用クローラをブロックし、別途、OpenAIOpenAI(米国)に対してAI 学習及びAI による要約等の生成に関する記事データのライセンスを提供している 事例等がある。
31 この点に関して、例えば、r obots.txt において、あらゆるAI 学習用クローラをブロックする措置までは取られていないものの、あるAI 学習用クローラについてはこれをブロックする措置が取られているにとどまるといった場合でも、主要なAI 学習用クローラが複数ブロックされているといった場合であれば、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることを推認させる一要素となると考えられる。この点に関しては、現状ではr obots.txt において、あらゆる種類のクローラをブロックする措置は取り得ても、AI 学習用クローラに限ってこれらを全てブロックするという措置は取ることができないという技術的限界があるところ、将来的には、AI 学習用クローラに限ってこれらを全てブロックすることを可能にするような技術的方式が確立されること等により、AI 学習データ収集を行う者にとっての明確化が図られることが期待される。
robots.txtとは、ウェブサイトの管理者がサーチエンジンのクローラー(ロボット)に対して、サイト内のどのページやディレクトリをクロールしてよいか、あるいはクロールしてはいけないかを指示するためのテキストファイルです。
つまり著作権を保有する側は、 robots.txtでAIのクローリングを除外する設定をすることができ、この措置(robots.txtを記載しておくこと)を講じることは、法的な判断基準となる、ということだと認識できます。
そのため、 AI 学習のための著作物の複製等を防止する技術的な措置が講じられており、かつ、このような措置が講じられていることや、過去の実績(情報解析に活用できる形で整理したデータベースの著作物の作成実績や、そのライセンス取引に関する実績等)といった事実から、当該ウェブサイト内のデータを含み、 情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合には 31 、この措置を回避して、クローラにより当該ウェブサイト内に掲載されている多数のデータを収集することにより、AI 学習のために当該データベースの著作物の複製等をする行為は、当該データベースの著作物の 将来における潜在的販路を阻害する行為 として、 当該データベースの著作物との関係で、本ただし書に該当し、法第30条の4による権利制限の対象とはならない ことが考えられる32 33。
結論とまとめ
法的文章は非常に長ったらしく、分かりづらいということが改めてわかりましたが、今回読み取った文章からは、 「Web上で(販売されておらず)広く一般公開されている情報(オープン情報)を、クローリングまたはブラウザ等で収集し、それをRAGとして扱って生成AIに出力させること」が、著作権上で違反となるかはまだ明確になっていない、ということです。
「ニュース記事や番組データは著作物である」ことは明らかだと思われるので、 「ニュース記事や番組データをRAGにかけることは、情報分析に当たるのか否か。情報分析に該当する場合、著作権者の利益を不当に害しているか」 ということが、これからの焦点とされるのではないでしょうか。
なお「利益を不当に害する」というのは、資料では本来あるべき販売機会を喪失したというニュアンスで使われているようです。そして本来あるべき販売期間を主張するためにも、著作権者側はrobots.txtに明記しておいたほうが良い、ということのようです。
今後は、著作権保有側は、robots.txtにAIクローラーの除外明記をした上で、法第30 条の4ただし書の「著作権者の利益を不当に害することとなる場合」に当たると主張し、一方で生成AI作成・利用側は「享受目的には当たらず情報分析に当たる」ことを主張する、というような展開が想定されます。
生成AIは新しい技術故に、多くのルールがこれから新たに作られていくものだと思われます。
広報担当にとっては、画像生成であればまずは Adobe FireFly のような学習データに著作権抵触データを使っていないツールを使うことが重要となるでしょう。
Adobe Firefly を適切に活用するための著作権との付き合い方 第4回(Adobe blog)
テキストデータのRAGに関しては、これから明確になっていくと思いますので、絶えず動向をチェックしつつ、最新の情報を確認することが重要となります。
今後も時勢に合わせて法律や解釈が常に変化することも考慮しながら、生成AIを効率的に活用することが生産性アップのポイントと言えるでしょう。
以上、生成AIのRAGと著作権のまとめでした。
▼生成AI関連の記事一覧
AIを活用した海外のPRサービス5選PropelなどAIを活用した海外のPRサービス5選を紹介します。広報・PR支援の株式会社ガーオン
【Dify活用】生成AIで広報リサーチ業務を行う方法ノーコードLLM開発ツールDifyを活用して、効率的にニュースのリサーチを行う方法を解説します。広報・PR支援の株式会社ガーオン
生成AIで良質なプレスリリースを書くコツ生成AIを使って読みやすく質の高いプレスリリースを作成するためのポイントを解説します。広報・PR支援の株式会社ガーオン
生成AI時代のデータを活用した広報PR戦略生成AI時代の検索データを活用した広報PR戦略を解説します。広報・PR支援の株式会社ガーオン
広報業務にChatGPTを活用する7つの方法【プロンプト付】広報業務にChatGPTを活用する7つの具体的な方法を解説し、プレスリリースの作成方法などのプロンプトエンジニアリング、差別化ポイントなどを解説します。広報・PR支援の株式会社ガーオン