検索の景色が変わった

数年前までは、ノートPCを買うとき、Google で「ノートPC おすすめ 20万円以下」と検索するのが当たり前でした。比較記事や価格.com で候補を調べ、自分でスペックや口コミを比較し、最終的に1台を選ぶ。選択の主導権は、利用者自身の手にありました。
今は状況が一変しています。ChatGPTに「動画編集もたまにやる在宅ワーカー、予算20万でおすすめは?」と尋ねれば、AIが瞬時に3台の候補と選定理由を示してくれます。多くの人はこの提示された3台から選び、わざわざ4番目以降の選択肢を探すことはほとんどありません。
結果として、AIが選ばなかったメーカーや製品は、消費者の購買プロセスにそもそも入りません。いくら広告や店舗展開に力を入れても、AIの「おすすめ3台」に入らなければ、ユーザーには届かない時代です。
つまり、選択の主導権が人間からAIに移っています。
- 従来:Googleや価格.comで10台以上が並び、利用者が自ら比較検討していました
- 現在:AIが3台のみを提示し、その中からしか選ばれません
広報・マーケティングの現場でも、この本質的な変化にまだ戸惑いを感じる方が多いかもしれません。AIに選ばれなければ、消費者の選択肢に入ることすら難しい時代がすでに始まりつつあります。
数字で見る地殻変動
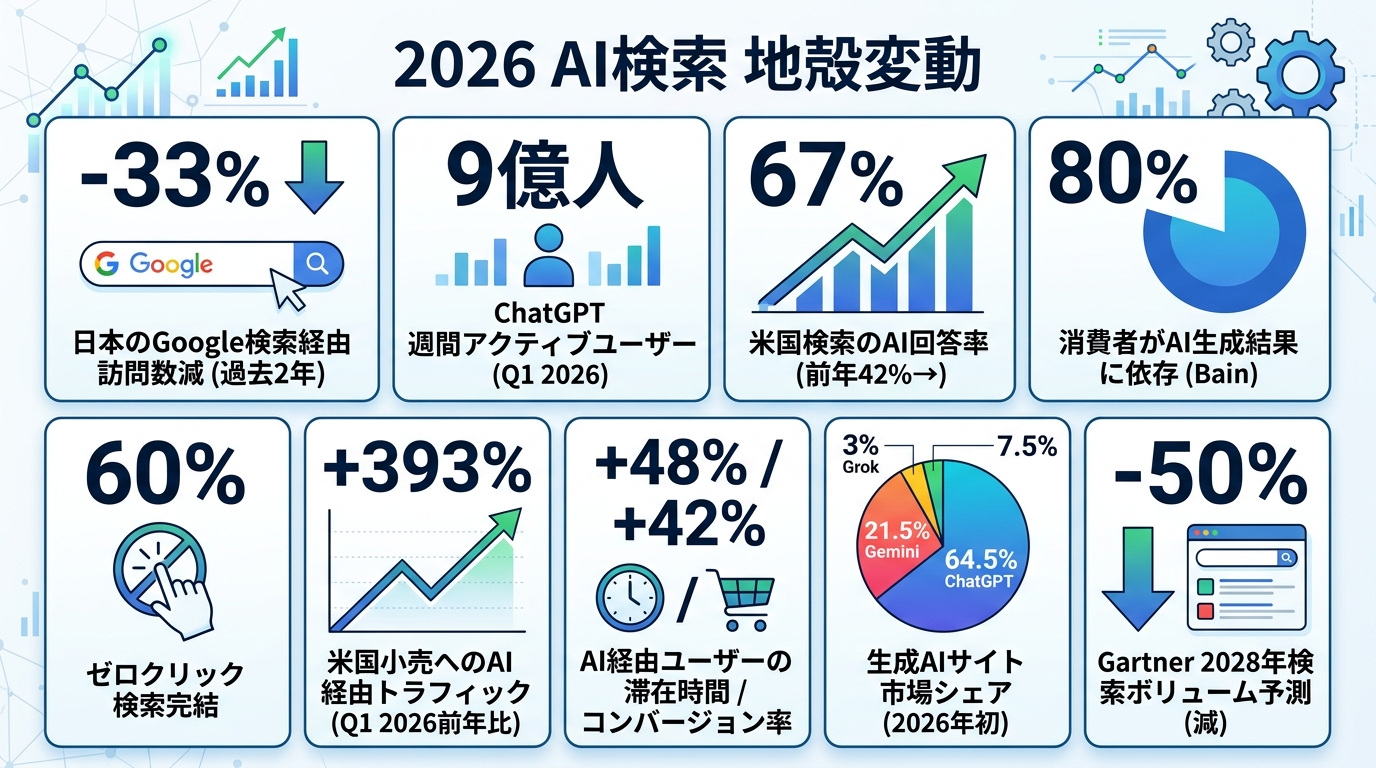
実際のデータでも変化は明確です。日本のGoogle検索経由の訪問数は、過去2年で33%減少しました(日本経済新聞、2026年2月)。 ChatGPTの週間アクティブユーザーは9億人に達し(OpenAI、2026年Q1)、米国では検索クエリの67%がAI回答を返すようになりました(前年は42%。MIT主導 24,000クエリ研究)。 Bain & Companyの調査では、消費者の80%がAIの生成結果に依存し、検索の60%がゼロクリックで完結しています。
小売の変化はさらに極端です。Adobe Digital Insightsによれば、米国小売サイトへのAI経由トラフィックは2026年Q1で前年比+393%。AI経由で訪れたユーザーは通常顧客より滞在時間+48%、コンバージョン率+42%。「AIから来た客のほうがよく買う」という逆転が起きています。
ただし、この変化はChatGPT一強で進んでいるわけではありません。Similarwebによると、生成AIサイトの市場シェアは ChatGPT が86.7%(2025年)から64.5%(2026年初)へ急低下し、Gemini が21.5%まで急伸、Grokも3%を超えました。
「ChatGPT対策だけしておけば足りる」という前提も、もう成り立ちません。
Gartnerは2028年までに従来の検索ボリュームが50%減ると予測しています。「AIに選ばれる」が、新しい事業課題になりました。
メディアは、AIが最初の読者になり、最初のフィルターになる
ここで覚えておきたい一文があります。マシンリレーションズ(Machine Relations)提唱者のJaxon Parrott氏(AuthorityTech社CEO)が、Entrepreneur誌2026年5月の寄稿で書いた言葉です。
「メディアは、AIが最初の読者になり、最初のフィルターになった。」
掲載記事を読むのは、もう人間が最初ではありません。 AIが先に読み、AIが「あなたのブランドを引用する価値があるか」を判定し終えてから、ようやく人間がその結果を目にします。
広告も検索もコンテンツも、この事実を起点に組み直さなければなりません。
AIは何を根拠に候補を挙げるか

ではAIは、どんな基準で候補を選んでいるのか。ここで Jaxon Parrott氏 が、業界全体をひっくり返す一言を放ちました。
「『AIでの順位』を出すツールは、すべてデタラメである。」
これは大きな話題となったようです。世界中のAI可視性ツール市場には、巨額の投資が集中していました。Profoundはシリーズ C で 96M ドル(約140億円)を調達し、評価額10億ドル(約1,500億円)のユニコーンに到達しています。Parrott氏は、そのビジネスの前提が根本から間違っていると指摘しました。
パラダイムシフト:「第一想起」から「集合メンバー」へ
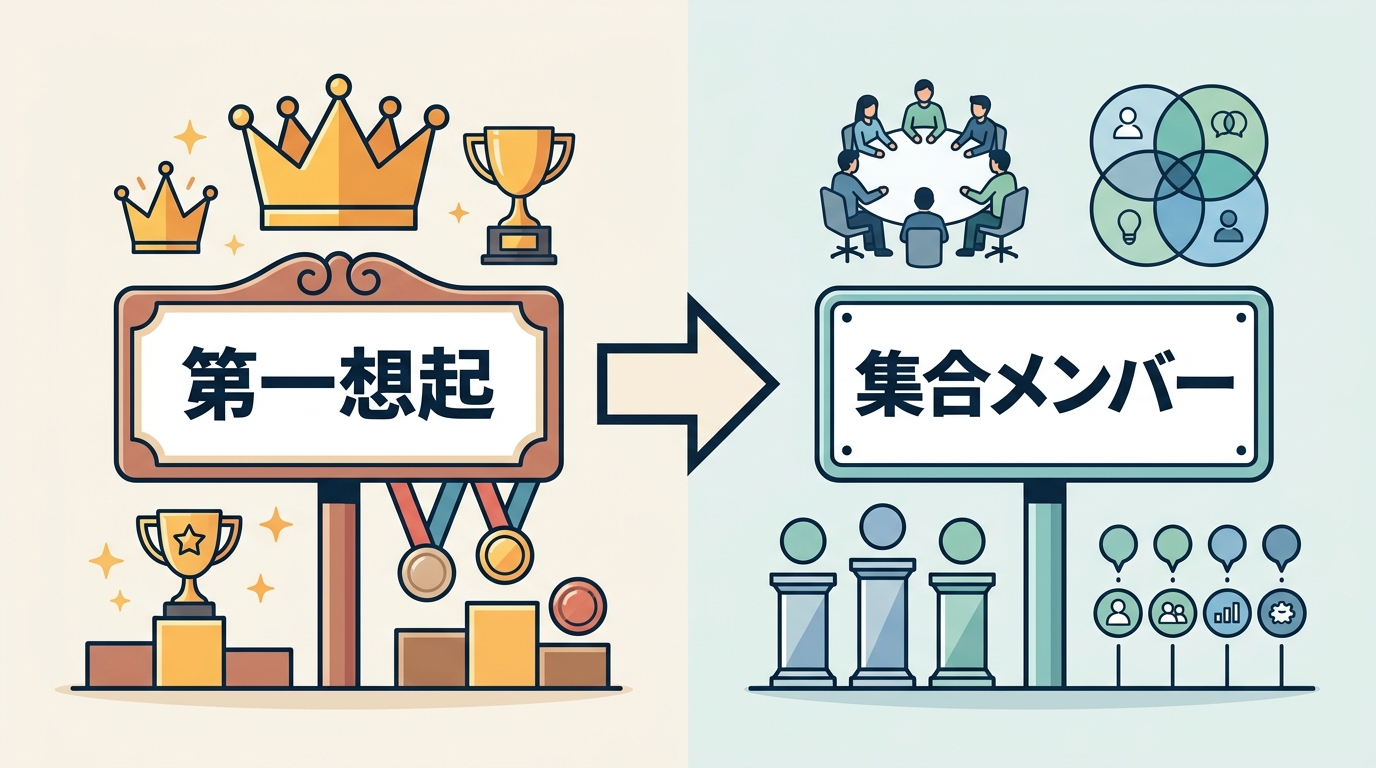
マーケティング業界はこれまで、第一想起(top-of-mind awareness)を最重要のブランド指標と見なしてきました。
「洗剤といえば?」と聞かれて最初に出てくる名前が「アタック」。2番目・3番目に挙がる名前には、消費者行動への影響がほぼありません。勝者総取り型の論理です。 この前提でブランド戦略を組むなら、「1位を取るか、取らないか」のゼロイチ勝負になります。
AI時代では、この前提が崩れます。AIは質問に対して複数候補を並べて返します。
- 「おすすめの洗剤を3つ挙げて」→ 3社が並列で提示される
- どの順番で並ぶかは応答ごとにランダム
決定的な問いは「3社のうちの1社になれるか」に変わりました。「1位であること」ではなく「集合に入っていること」が、購買行動に直結する指標になっています。これがParrott氏のいう「考慮集合こそ本質」という主張に繋がります。
考慮集合とは何か
Parrott氏が示した言葉「考慮集合(こうりょしゅうごう/consideration set)」。
この考慮集合とは、AI内部のベクトル空間に存在する、目には見えない集合を指す言葉として定義されています。AIは確率分布に従って出力するため、出てくる答えは毎回違います。「その集合に何が入っているか」は、実際に質問を投げてみないと分かりません。
しかし、同じカテゴリーで質問を繰り返していくと、ある種の輪郭が見えてきます。石の中に埋もれた彫像を少しずつ削り出すように、100回・200回と問いを重ねるうちに、「このカテゴリーでAIが即座に呼び出せる候補」の形が浮かび上がってきます。 これが考慮集合の実態です。
順位は存在しない(Fishkin研究)
「彫像の輪郭」を実証データで示したのは、SparkToro社CEO Rand Fishkin氏(元Moz創業者)らによる2,961プロンプト検証です(SparkToro、2026年1月公表/実施は2025年11〜12月)。
研究の要点:
- 600人のボランティアが12種類のプロンプトを3つのAI(ChatGPT/Claude/Google AI Overviews)に投げ、合計2,961プロンプトを実行
- 同じ質問を繰り返しても、同じブランドリストが返る確率は1%未満(順位はランダム振動)
- 一方、トップブランドは応答の55〜77%に出現(例:ヘッドホンカテゴリーで Bose、Sony、Sennheiser、Apple の4社が994件の応答のうち 55〜77% の範囲に登場)
55〜77%は観察された出現率の範囲で、「○%超えたら合格」という閾値ではありません。 カテゴリートップ帯のブランドが、応答のおおよそ半数以上に安定して登場するという事実を示しています。
順位(表面の粉)は削る角度で変わります。彫像の本体(考慮集合)は安定しています。この非対称性が、MR理論の実証的な根拠です。
検索トリガー型でも、結論は同じ
実際のAIは、質問に応じてリアルタイム検索を走らせることがあります。ChatGPT、Perplexity、Google AI Overviewsなどは、「おすすめの◯◯」と聞かれると内部で検索を実行し、その結果を元に候補を抽出します。
一見、これは「過去のアーンドメディア蓄積」より「今の検索順位」を重視する仕組みに見えます。しかし実態は逆向きです。
Perplexityのアルゴリズムは公式には公開されていません。ただ、SEO研究者の Metehan Yesilyurt がブラウザのリクエストを逆解析し、内部パラメータ59項目を 抽出した分析を公開しています(Search Engine Land、2025年8月)。

そこから見えるのは、エンティティ検索で3段階のリランキング(L3 reranker)が 動き、Amazon・GitHub・LinkedIn・Coursera など、Perplexity社が手動で登録した 権威ドメインのリストが構造的にブーストされる仕組みです。
つまり、AIがリアルタイムで情報を引いてきても、外部の権威シグナルが構造的に 優先されます。これは広報・PR業界で「Tier 1(ティアワン)メディア」と呼ばれる、 記者・編集部の手による信頼度の高い大手報道機関(米国ではForbes・Wall Street Journal・TechCrunch、日本では日経・東洋経済・ITmedia など)が該当します。 これら Tier 1 に取材されているかどうかが、AI可視性に直結します。
検索トリガー型のAIでも、アーンドメディアの重要性は下がるどころか、むしろ上がっています。
ただし新しい要素が加わります。フレッシュネス(鮮度)です。Perplexityには約30日のフレッシュネス窓があり、更新が止まるとコンテンツは急速に可視性を失います。「半年前に日経に1本載った」では足りません。
Machine Relations系のメディア分析によれば、AI可視性の70%は6ヶ月で失われます("Citation Drift" 現象)。一発取材では効きません。継続的にメディア露出を積み上げる運用が必要な世界になりました。
どうすれば考慮集合に入れるのか

ではどうすれば考慮集合に入れるのか。Parrott氏の答えは、意外なほど伝統的です。
「権威性の高いメディアに、あなたの会社の記事が載ることです。」
新聞や業界誌に取材されます。そのURLがインターネット上に残ります。AIは学習・参照の過程でその記事を読み、「この会社は日経でもITmediaでも名前が出てくる。候補に入れておこう」と認識します。
具体的な数字:
- AI引用の82〜89%はアーンドメディア(=外部のメディア掲載)から来る(Muck Rack 2026年版で82%、Fullintel-UConnで89%)
- AuthorityTechが8,000万件のAI引用データを分析しても、結論は同じ。第三者編集ソースが82〜89%を占める
- ブランド言及はバックリンクの3倍、AI引用との相関が強い(AuthorityTech自社研究)
そして決定的な一言が来ます。
「自社サイトをいくら磨いても、考慮集合には入れません。」
多くのマーケ担当者は「自社のオウンドメディアを充実させよう」「スキーマを実装しよう」と考えます。それ自体は間違っていません。ただし、Parrott氏に言わせれば、それは考慮集合に入った後に効く話。まず集合に入るには、第三者メディアに取り上げてもらう必要があります。
メディア掲載は完成品ではなく、原材料に変わった

2026年5月、Parrott氏はEntrepreneur誌への寄稿で、PR業界の常識を再定義する一言を放っています。
「The placement is not the product anymore. The placement is raw material.」 (メディア掲載は完成品ではなくなった。原材料に格下げされた。)
従来:記事掲載 → ソーシャル拡散 → 営業活用(人間が読み手)
新モデル:掲載 → AIが引用可能か判定 → 人間が発見
記事の見栄えやページビューではなく、「AIがこの記事のどの一文を抜き書きできるか」が新しい評価軸になりました。 同じプレスリリースでも、AIが引用しやすい構造かどうかで結果が大きく変わります。
| ✅ AIが抽出できる | ❌ AIが抽出できない |
|---|---|
| 「中堅金融部門の決算締め時間を40%短縮」 | 「業界をディスラプトする」 |
| 「2025年売上は前年比300%増」 | 「カルチャーを革新する」 |
| 具体数値・対象・効果の三点セット | 抽象スローガン・自画自賛 |
広報の基礎である「具体的な数値・事実の表現」が、AI引用でも効きます。
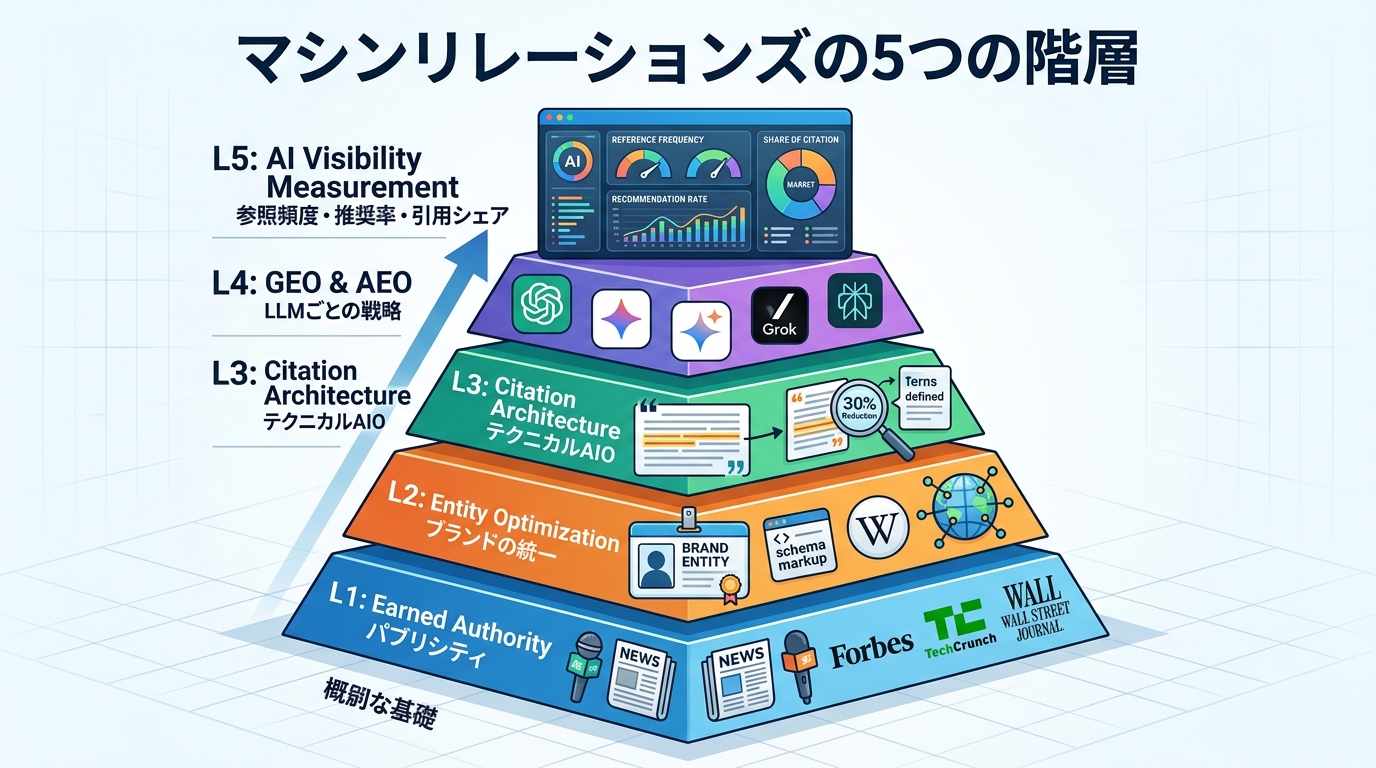
マシンリレーションズの5つの階層
Parrott氏は、MRを5つの層で説明しています。
日本語で言い換えると
| 層 | 原語 | 日本語 |
|---|---|---|
| L1 | Earned Authority | パブリシティ |
| L2 | Entity Optimization | ブランドの統一 |
| L3 | Citation Architecture | テクニカルAIO |
| L4 | GEO & AEO | LLMごとの戦略 |
| L5 | AI Visibility Measurement | 参照頻度・推奨率・引用シェア |
この並びを見て気づくのは、MRが「新しい何か」ではなく、既存のPR・マーケ・データ業務をAI時代向けに再配線したものだという点です。L1は広報部の仕事、L2はブランド管理、L3はコンテンツ制作・SEO、L4はデジタルマーケ、L5はデータ分析。どれも既存の職能です。
L1:パブリシティ(誰かが評価する層)
Parrott氏の原典
Parrott氏がL1 "Earned Authority"(獲得された権威性)を、machinerelations.aiで次のように定義しています。
"Tier 1 media placements in publications AI engines trust and cite — Forbes, TechCrunch, Wall Street Journal." (AIエンジンが信頼し引用するパブリケーションでのTier 1メディア掲載。Forbes、TechCrunch、Wall Street Journal)
核心主張:
"You cannot optimize your way into the consideration set from inside your own properties." (自社プロパティ内での最適化だけでは、考慮集合に入ることはできない)
Parrott氏が根拠として引用する数字は3つ:
- AI応答の82〜89%がアーンドメディアを引用(Muck Rack 2026年版で82%、Fullintel-UConnで89%)
- アーンドメディア掲載は自社コンテンツの3.25倍のAI引用を生む(AuthorityTech自社研究)
- AI引用の65.3%が権威ドメイン(Ahrefs Domain Rating 80以上、=世界の主要紙・通信社・大手プラットフォーム)から(Ahrefs分析)
自社が書いた記事より、第三者が自社について書いた記事のほうが3倍以上AIに参照されます。これがParrott氏がL1を5層の基盤に据えた根拠です。
日本実務への翻訳(当社解釈)
Parrott氏の例示(Forbes / TechCrunch / WSJ)は、そのまま日本には当てはまりません。当社で別途Brand Radar分析を行った結果、日本のメディア重み付けは米国とは明確に異なることが判明しました。
AIはヤフーニュースよりもNHK優先!? AI時代のPR戦略とは|PRナビ子ちゃん
当社の独自分析でわかってきたのは、LLMモデルごとに引用するメディアが大きく異なることです。同じ質問に対して、ChatGPT・Claude・Gemini・Grok・Perplexity の TOP5 引用ドメインを比較すると、TOP3 が他のLLMと重ならないケースもあるほどです。
ただし、業界カテゴリごとには「LLM横断で共通して引用される基盤メディア」が存在します。BtoC 消費財なら mybest、というように。広報の最初の一手は、自社のカテゴリで「LLM 横断の基盤」になっている媒体に取材を取ることです。
LLM別の性格として観察できる傾向は次の通りです。
- ChatGPT:海外英文専門サイト+当事者公式サイトを最上位に置く(指名検索的)
- Claude:日本のキュレーション・比較まとめサイト中心
- Gemini:日本のEC・量販モール・ブログ中心、引用件数も最多
- Grok:Reddit・YouTube・国内雑誌(コミュニティ動画寄り)
- Perplexity:楽天検索・kakaku・note など比較系+コミュニティ
- Google AI Overview/Mode:YouTube・mybest 中心、Google エコシステム内で完結
ニュース・社会トピック領域に限っては、別の検証で NHK・共同通信・官公庁が LLM 横断で上位に来る傾向が出ています(AIはヤフーニュースよりもNHK優先!? AI時代のPR戦略とは)。商品・サービス選定系のカテゴリとは情報源の力学が異なります。
以上を踏まえると、カテゴリ別・LLM 別に最適化されたメディア戦略が必要になります。
このカテゴリ別・LLM別の引用パターンを定点観測するのが、当社が提供する PRナビ AI Pulse の中核機能です。複数のLLMに対する自社・競合・業界基盤メディアの引用シェアを継続的に追跡し、自社の不足箇所と打ち手を可視化します。

引用元はクエリタイプで明確に分岐します:
- 既知ブランドの事実確認(例「○○社の創業年は?」):PR TIMESがChatGPTで日約9万回引用(全ドメイン2位)と圧倒的。ただしノンブランド検索では引用ゼロ
- 評判・比較検討(例「○○業界のおすすめ3社」):日経 190回 / ITmedia 97回 / 東洋経済 47回が中心
実装への示唆:
- プレスリリース配信(PR TIMES等)は「ブランド認知後のファクトブースト」として機能。未知段階での考慮集合入りには無力
- 考慮集合入りを狙うなら、日経・ITmedia・東洋経済などの編集記事での被取材が最短
- NHK・共同通信・官公庁など権威系への言及は、業界動向取材やコメント提供で少しずつ積み上げる
米国MRの「Forbes / TechCrunch / WSJで3本/四半期」という目安を、日本では「日経/東洋経済/ITmediaで3本/四半期」に読み替えるのが現実的です。
L2:ブランドの統一(同一法人と認識される層)
Parrott氏は、Machine Relations公式サイトでL2を以下のように定義しています。
"Structured identity signals that machines can verify and resolve — consistent entity definitions, schema markup, knowledge graph presence across the brand's digital footprint." (AIが検証・解決できる構造化されたアイデンティティ信号。一貫したエンティティ定義、スキーママークアップ、ブランドのデジタル足跡全体にわたるナレッジグラフ上の存在)
要点は3つ:
- 一貫したエンティティ定義
- スキーママークアップ
- ナレッジグラフ上の存在
Parrott氏自身は「どの情報源が正典か」は明言していません。あくまで「ブランドのデジタル足跡全体」を通じて、複数の構造化された信号が互いに矛盾しない状態を求めています。
日本実務への翻訳。整備効果が大きい3つの場所:
- Wikipedia記事:ChatGPTの学習データで影響力が大きい
- Schema.org Organization:公式サイトにマークアップすれば、AIクロール時に確実に拾われる
- Wikidataエントリ:ナレッジグラフ上の明確な識別子として機能
実務で本当に問題になるのは「事実の矛盾」です:
- 設立年が資料ごとに違う(Wikipedia「2018年」/公式「2017年」/LinkedIn「2019年」)
- 旧社名・新社名・子会社ブランドが混在し、どれが親法人かAIから見て曖昧
- Wikipedia記事がそもそも存在しない
この3つを整え、複数の情報源が互いに補強し合う状態になっていれば、L2の要件を実質的に満たします。
L3:テクニカルAIO(抜き書きされる層)
AIが段落を抜き書きしやすい構造にコンテンツを設計する。具体的には:
- Answer-First構造(結論を冒頭150字以内に置く)
- 統計・数値の提示(「30%削減」など抽出可能な形)
- 定義の明確化(専門用語を一文で定義)
- 引用タグ(誰の発言・誰のデータかを明示)
- 段落単位で意味が完結(抜き出しても意味が通る)
Parrott氏が示す重要な数字:ChatGPTが引用するURLの88%は、Google検索の上位10件に出てきません(Ahrefs 15,000プロンプト研究、2026年)。AIは「ページ全体のランキング」を見ているのではなく、「引用できる段落」を直接探しています。
L4:LLMごとの戦略(各AIに方言を合わせる層)
ChatGPT・Claude・Gemini・Perplexity・Google AI Overviewsは、それぞれ好む情報源が違います。
- ChatGPT:Wikipedia優位
- Perplexity:Reddit等のコミュニティ優位
- Google AI Overviews:分散型、多様なソース
- Claude:学術・テクニカルドキュメント寄り
L3(テクニカルAIO)が「どのAIでも必要な汎用的な技術基礎」だとすれば、L4は「各AI向けのチューニング」にあたります。汎用対策と個別対策の二段構えです。
冒頭で触れたシェア多極化(ChatGPT 64.5% / Gemini 21.5% / Grok 3%超)が進んだことで、「ChatGPTだけ対策しておけばよい」時代は終わりました。Geminiで存在感がない企業は、Google検索ユーザーの21.5%から事実上消えています。L4の重要性は、2025年と比べて格段に上がりました。
L5:参照頻度・推奨率・引用シェア(測る層)
Parrott氏が名指しで推奨するメトリクスは3つ。ただし「順位」は測りません。
| メトリクス | 測るもの | 性質 | 答える問い |
|---|---|---|---|
| 参照頻度 | AIが自社を言及した回数 | 量(絶対数) | そもそも候補に入っているか |
| 推奨率 | 言及されたうち「おすすめ」として推された比率 | 質(比率) | 入ったとき推奨されているか |
| 引用シェア(Share of Citation) | 競合含む市場全体での自社の引用占有率 | 相対 | 競合と比べ、どこまで支配的か |
3つを並行で見ないと診断が片側に寄ります。参照頻度だけ追うと「並んでるだけで推奨されない」状態が見えません。推奨率だけだと「そもそも候補にすらいない」期間が見えません。
「Share of Voice」から「Share of Citation」へ
Parrott氏が2026年5月のEntrepreneur誌寄稿で打ち出した新指標が「Share of Citation(引用シェア)」です。従来マーケティング業界が使ってきた「Share of Voice(言及シェア)」を、AI時代向けに置き換える概念です。
| 旧:Share of Voice | 新:Share of Citation |
|---|---|
| 人間に何回見られたか | AIに何回引用されたか |
| メディア露出量・SNS言及量 | AI回答内での引用占有率 |
| ブランド認知の代替指標 | 考慮集合内での占有率 |
この転換は、単なる用語の差し替えではありません。「人間に届いたか」ではなく「AIに引用されたか」を一次指標に据えるという、測定哲学の刷新です。
Parrott氏 の思想は、他のAI可視性ツールと真逆
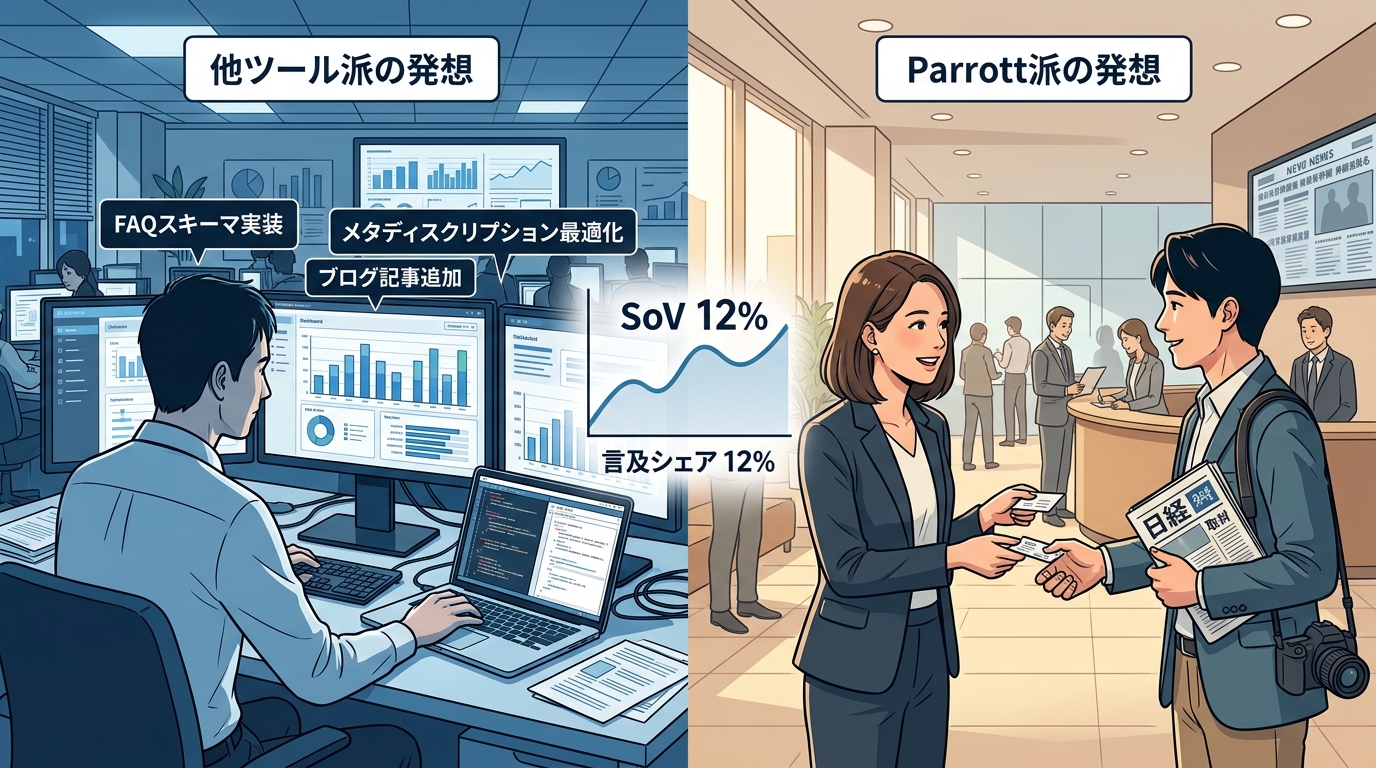
代表的ツールである、Profound も Peec AI も Ahrefs Brand Radar も、SoV(言及シェア)という指標を出します。ところが Parrott氏 の打ち手は、他社ツールと正反対です。
| 他ツール派 | Parrott氏 派 | |
|---|---|---|
| 介入する場所 | 自社サイトの中 | 自社サイトの外(メディア) |
| 主な打ち手 | FAQスキーマ・ブログ追加・メタディスクリプション最適化 | 記者取材・Tier 1 メディアでの被取材 |
| 動かす部署 | マーケ・SEO担当 | 広報・PR担当・経営陣 |
指標は同じ SoV です。違うのは、その数字を見た後にどこに介入するか。 サイト改善 に動くのか、パブリシティ獲得 に動くのかという、思想の根本的な違いです。 Parrott氏の考えはより広報・PR寄りに振れています。
なぜこの差が致命的か
自社サイト改善は、効果が数週間で頭打ちになります。スキーマもFAQも、ある程度 整えたら追加リターンが乏しくなります。 また手法が確立されたら他社が真似しやすく、いずれコモディティ化する弱点もあります。
記事などのアーンドメディア掲載は、時間はかかるが効果が複利で積み上がります。日経1本の取材は、永続的にURLが残り、関連記事からリンクされ、他メディアが参照し、AIの 学習データ・検索リランカーに繰り返し取り込まれます。
結果、他ツール派は「ダッシュボードを磨く作業」に追われ、Parrott氏 派は「外で有名に なる作業」に投資します。半年後、2社の考慮集合での立ち位置には桁違いの差が生まれます。
AI可視性ツール市場の地殻変動
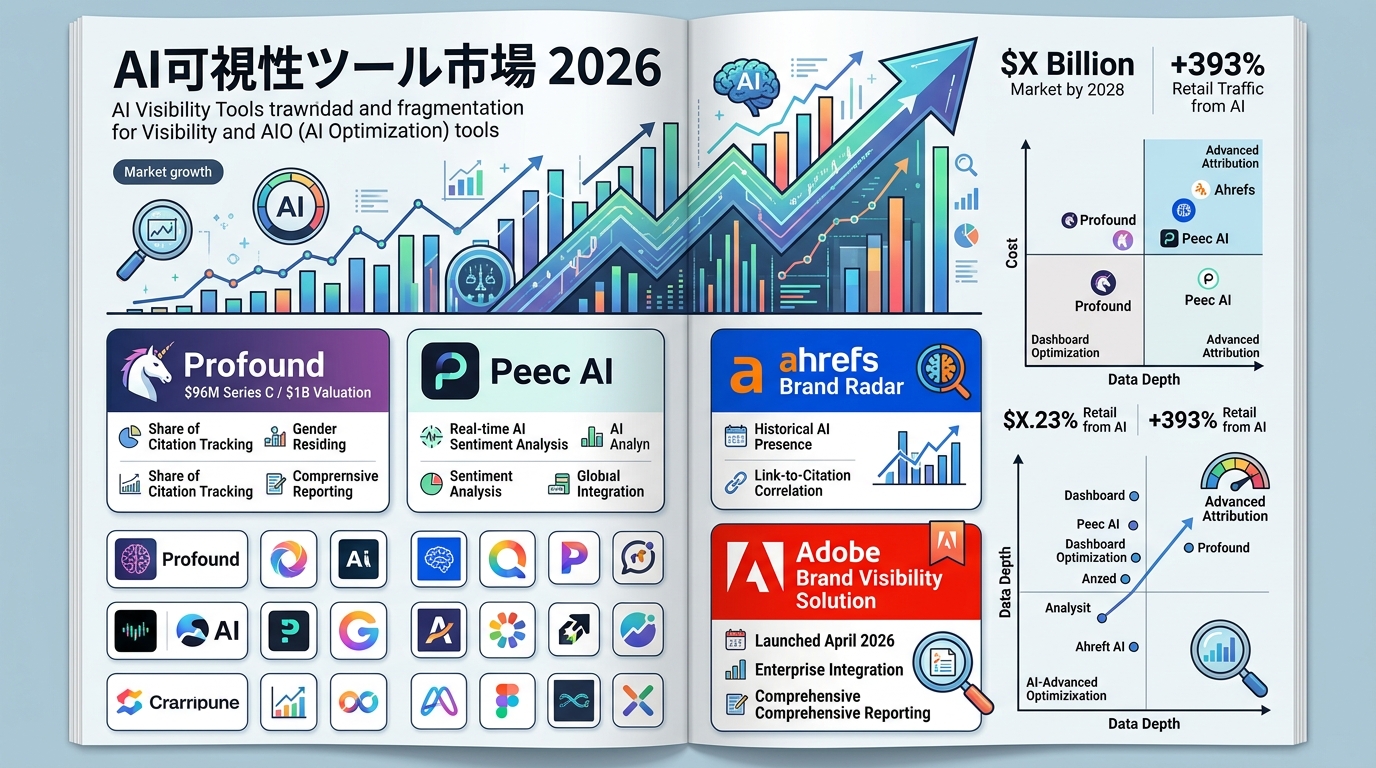
2026年に入って、市場の景色そのものが変わりました。
- Profoundが96Mドル(約140億円)のシリーズCを調達、評価額10億ドル(約1,500億円)でユニコーン入り。ダッシュボード型ツールの覇権争いが本格化
- Adobeが2026年4月「Brand Visibility Solution」を発表。マーケティング大手の参入で、AI可視性は単独カテゴリーとして公式に認知された
AI可視性は「実験段階の新領域」ではなく、AdobeやSalesforceクラスの大手が戦略的に投資する成熟市場に入りました。同時に C-SEO Bench(NeurIPS 2025)が示した「採用者が増えるほどテクニカルAIOの効果が減衰する」現象も顕在化しています。自社サイト最適化の競争は、これからゼロサム化が進みます。
PR代理店業界もまた、地殻変動の只中にある
ここで見落としてはいけない論点があります。Parrott氏自身がSEOツール業界の人間ではなく、10年PR業界の中で生きてきた人物だという点です。
米国のPR業界は2025〜2026年、目に見える縮小に入りました。
- 世界最大手のEdelmanはグローバル売上が3年連続で減収。2025年は前年比-4%、米国売上は-8.1%。330人のレイオフと6ブランドの廃止を実施(PRWeek、2026年)
- WPPは売上-3.6%、税引前利益-26%、配当を62%カット(The Guardian、2026年2月)
- WPP傘下のPR2社(BCW、Hill & Knowlton)は合併して「Burson」に再編、6,000人体制(Marketing Interactive、2026年)
旧来のPR大手が縮小する一方で、Parrott氏が立ち上げたAuthorityTechのような「AIネイティブ・アーンドメディア代理店」が台頭しています。 Entrepreneur誌の寄稿は、その新興側が経営者向けメディアで「PR業界全体が構造的に書き換わった」と公式に宣言した文書です。
PR業界の外、たとえばSEOツール業界の人が「PRは終わった」と言うなら、それは ただのポジショントーク(「うちのツールに乗り換えろ」という営業)に過ぎません。 しかしParrott氏は PR 業界に10年身を置いた当事者です。業界の中の人が、自ら 「伝統的なPRのやり方は死につつある、再定義しなければ」と書きました。この自己 批判こそが、Entrepreneur誌寄稿の重みとして注目されています。
米国のPR会社は、静観しているわけではありません。たとえば米5W Public Relationsは2026年5月、独自調査「AI Platform Citation Source Index 2026」を発表し、ChatGPT・Claude・Perplexity・Gemini・Google AI Overviews 内でブランド可視性を決定する50サイトを特定しました(2024年8月〜2026年4月の 6.8億件のAI引用 を6つの研究から統合、Redditが全エンジン約40%で1位、トップ15サイトがAI回答パイプラインの68%を占有)。
同社は「Google検索の上位順位とAIに引用されるソースの重なりが、70%から20%未満に崩落した」という別調査も同時期に公表しています。PR会社自身が「AI引用源」を業界資源として公表する動きが、米国では始まりました。
LLMO関連の調査・発信はSEO会社・テック系スタートアップが先行 しており、日本のPR業界は、まだこの構造変化に明示的に応答できていないのが現状です。 本来ならばいち早く『広報会議』誌などが取り組むべき領域ですが、なかなか動きが遅いようです。
日本版MRの二段階メトリクス
Parrott氏のSoV論を日本の実務現場に落とすと、こう整理できます。
| メトリクス | 性質 | 使い方 | 担当 |
|---|---|---|---|
| 引用シェア(SoC) | 結果指標(outcome) | 2値判定(考慮集合に入っているか/いないか) | データチーム・経営企画 |
| パブリシティ件数 | 入力指標(input) | 量的KPI(月何件のTier 1掲載を取ったか) | 広報部・PR代行 |
引用シェアは結果指標です。直接は動かせません。他ツールは「SoVを上げるには自社コンテンツ改善を」と言いますが、Parrott氏論ではそこに天井があります。一方でパブリシティ件数は動かせます。広報部が「今四半期、Tier 1に3本取材を取る」と決めれば、行動で積み上がります。
L1(パブリシティ/アーンドメディア)→ L5(引用シェア)という因果関係があります。入力を管理すれば出力はついてきます。この運用が、日本企業がMRを実装する最も現実的な道です。
補足:賞味期限があるのはテクニカル側だけ
賞味期限があるのはL3(テクニカルAIO)の知見です。箇条書き、表形式、Answer-First、統計データの追加。これらの因果が解明された瞬間、テクニックは誰でも真似できるコモディティになります(NeurIPS 2025「C-SEO Bench」論文が示した「採用者が増えるほど全体の効果が逓減するゼロサム構造」)。
一方、L1(パブリシティ)はそもそもアンコントローラブル。日経の記者はあなたの稟議では動きません。因果が解明されようが、「実際にTier 1メディアで取材される」という実行障壁は残り続けます。だからこそParrott氏はL1を5層の基盤(foundation)に据えました。
最適化可能な層には賞味期限があり、最適化不可能な層には賞味期限がありません。この非対称性が、パブリシティを恒久的な差別化要素にしています。
日本企業に特有の落とし穴

ここまでがParrott氏の理論です。日本で実装するには、2つの修正が必要です。
落とし穴1:部署の壁
5層の担当は、日本企業ではバラバラです。
| 層 | 日本語 | 担当部署 |
|---|---|---|
| L1 | パブリシティ | 広報部 |
| L2 | ブランドの統一 | マーケ部 or 情シス |
| L3 | テクニカルAIO | コンテンツチーム |
| L4 | LLMごとの戦略 | デジタルマーケ部 |
| L5 | 計測 | 経営企画 or データ分析 |
これらの部署は、日本企業では普段まったく連携していません。広報部は「プレスリリースを年50本配る」がKPI。マーケ部は「リスティング広告のCVR」がKPI。この縦割りが、MR実装の最大の敵です。
落とし穴2:ソーシャルプラットフォームの位置づけ
Parrott氏の5層には、X(旧Twitter)やYouTube、noteといったソーシャルプラットフォームの位置づけが曖昧です。日本では、これは致命的です。
日本のAIが学習・参照しているコンテンツには、Xの長文スレッド、YouTubeの専門家動画、noteの解説記事が大量に含まれます。 米国のMR論ではあまり扱われない経路が、日本ではTier 1メディアと並ぶ重要な情報源になります。
明日からできる4つのアクション
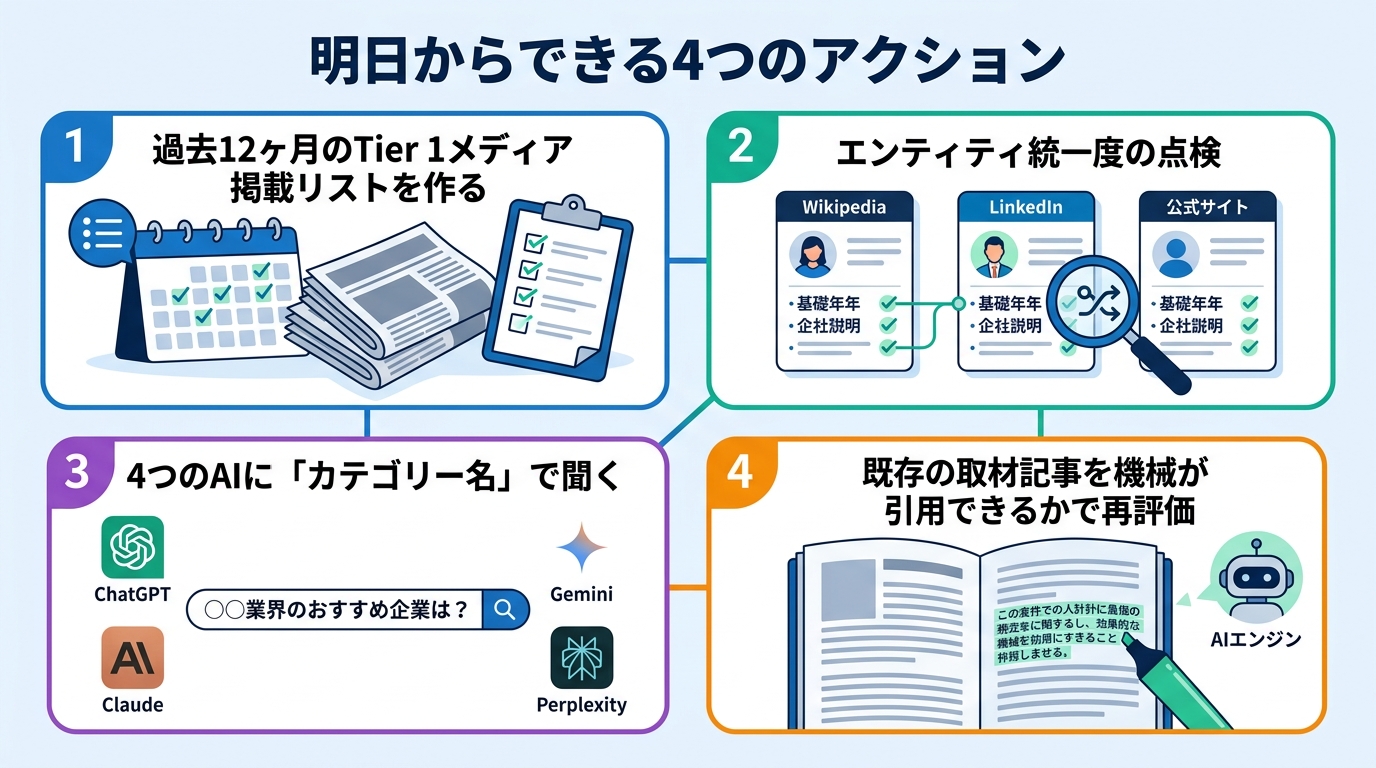
1. 過去12ヶ月のTier 1メディア掲載リストを作る
日経、東洋経済、ITmedia、業界専門誌など、AIが学習データとして取り込む可能性の高い媒体に絞って一覧化。「そのURLが生きているか」「AIが読めるHTML構造か」まで確認します。L1の可視化です。
2. 自社の「エンティティ統一度」を点検する
Wikipedia記事、LinkedIn企業ページ、公式サイトの会社概要で、社名表記・事業内容・設立年が一致しているかを確認。表記揺れがあるほど、AIはあなたの会社を別の法人として扱います。L2の第一歩です。
3. 4つのAIに「カテゴリー名」で聞く(自社名ではなく)
ChatGPT、Perplexity、Claude、Geminiで「〇〇業界のおすすめ企業は?」と聞き、自社が呼ばれるかを確認。 ブランド名で検索しても答えは出ますが、それは指名検索の世界。
考慮集合に入っているかを確かめるなら、自社名を含めずカテゴリー名だけで聞くのが鉄則です。
4. 既存の取材記事を「AIが引用できるか」で再評価する
過去のメディア掲載記事を1本ずつ開き、「この記事のどの一文をAIが引用するか?」を自問します。具体数値・対象・効果の三点セットがある段落は引用されやすい。「業界をリードする」「カルチャーを革新する」のような抽象表現しかない記事は、いくら掲載されてもAIには無視されます。次の取材依頼では、Parrott氏流の問いを編集者と共有してください。「この記事のどの一文を、AIエンジンが特定の質問への答えとして引用できますか?」
まとめ:たった1行で覚えるなら
「考慮集合のメンバーになること。それがマシンリレーションズ。」
- 何位かを測るな。集合に入っているかを見よ
- 自分で自分を褒めるな。誰かに褒めてもらう場所に出ていけ
- 1つの部署で完結させるな。広報とマーケとデータを束ねよ
- AIに引用される一文を、すべての取材で意識せよ
メディアはAIが最初の読者・フィルターになる時代です。企業に求められるのは、「人間に響く共感性・ストーリー性のある文章」と「AIが抜き書きできる事実」の両方を備えた発信です。LLMO対策という言葉は日本で急速に広まり、国内でも関連SaaSが2025年に相次いで立ち上がっています。これらは重要な動きです。ツール契約より先に、組織の縦割りをどう越えるか、L1(パブリシティ)をどう積み上げるか、という問いが来ます。
当社では、この理論を実装する形で、各種LLMの傾向を分析する「PRナビ AI Pulse」の提供を開始しました。業界・競合・ターゲット層は企業ごとに異なるため、すべての企業に個別設計でカスタマイズしたプランを提供しています。
詳しくはお問い合わせください。
参考文献
Parrott氏 / Machine Relations 関連
- Jaxon Parrott氏「Public Relations Has Become Machine Relations — Most Founders Have No Idea What This Means」Entrepreneur, 2026年5月5日

PR Worked for Humans. Now It Has to Work for Machines.
AI now decides whether your earned media gets surfaced, cited or ignored. Here is why founders need to rethink PR strategy right now.
Entrepreneur
- AuthorityTech「AuthorityTech Founder Jaxon Parrott氏 Defines Machine Relations」GlobeNewswire, 2026年3月19日 www.globenewswire.com/…-in-AI-Search.html
- Jaxon Parrott氏「AI Doesn't Have a Rank. It Has a Consideration Set.」AuthorityTech, 2026年 authoritytech.io/…n-set-is-real-2026
- Jaxon Parrott氏「How Perplexity Selects Sources」AuthorityTech, 2026年 authoritytech.io/…ces-algorithm-2026
- Machine Relations 公式サイト https://machinerelations.ai/
- AuthorityTech https://authoritytech.io
- Citation Drift: Why 70% of AI Visibility Vanishes in 6 Months(Medium / Machine Relations) medium.com/…-data-d7c2eea8e223
学術・第三者研究
- Rand Fishkin & Patrick O'Donnell「AIs are highly inconsistent when recommending brands or products」SparkToro, 2026年1月27日(実施期間:2025年11〜12月)

NEW Research: AIs are highly inconsistent when recommending brands or products; marketers should take care when tracking AI visibility - SparkToro
Editor's Note: We're hosted a webinar to walk through the findings of this study. You can watch it for free (no ads). The Problem: For the last few years,
SparkToro
- NeurIPS 2025「C-SEO Bench: Does Conversational SEO Work?」arXiv:2506.11097 neurips.cc/…iego/poster/121465
- MIT 主導 24,000 クエリ研究(前年比AI回答率 42% → 67%)arXiv:2602.13415
業界データ
- Muck Rack「What Is AI Reading? Updated for 2026」(AI引用の82%がアーンドメディア) muckrack.com/…ading-new-insights
- Fullintel-UConn 共同研究(AI引用の89%がアーンドメディア、ピアレビューAward受賞) fullintel.com/…-in-the-age-of-ai/
- Bain & Company「Goodbye Clicks, Hello AI」(AI依存80%、ゼロクリック60%) www.bain.com/…defines-marketing/
- Adobe Digital Insights「Q1 2026 AI Traffic Report」(AI経由小売トラフィック前年比+393%) business.adobe.com/…t-machine-readable
- Adobe「Brand Visibility Solution」発表 2026年4月 news.adobe.com/…isibility-solution
- Ahrefs 15,000 プロンプト研究「Only 12% of AI Cited URLs Rank in Google's Top 10」2026年 https://ahrefs.com/blog/ai-search-overlap/
- Similarweb「Generative AI Statistics for 2026」(ChatGPT 64.5% / Gemini 21.5%) www.similarweb.com/…/geo/gen-ai-stats/
- Profound シリーズC 96Mドル / 評価額10億ドル 報道 2026年
PR業界の構造変化
- PRWeek「Edelman 2025 global revenue down 4%; US revenue falls 8.1%」 www.prweek.com/…s-revenue-falls-81
- Marketing Interactive「Edelman lays off 330 people globally restructuring」 www.marketing-interactive.com/…ally-restructuring
- The Guardian「WPP to merge ad agencies and cut jobs amid AI threat」2026年2月26日 www.theguardian.com/…threat-advertising
- Marketing Interactive「WPP merges BCW and Hill & Knowlton into Burson」 www.marketing-interactive.com/…ll-knowlton-burson
日本市場データ
- 日本経済新聞「Google検索、日本で訪問数33%減」2026年2月
- 株式会社ガーオン「AIはヤフーニュースよりもNHK優先!? AI時代のPR戦略とは」note, 2026年4月
AIはヤフーニュースよりもNHK優先!? AI時代のPR戦略とは|PRナビ子ちゃん
- Gartner「Search volume forecast to 2028」