2026年、広報・PRの世界にAIが本格的に入り込んでいます。海外ではAIが「この記者にピッチすべき」と推薦してくれるPRツールが次々と登場し、従来のメディアリスト作成の常識を覆しつつあります。
HeyJared、Presscloud、Cision、Muck Rack——こうした海外PRテックは、大量の記事データをAIで解析し、最適な記者を自動でマッチングする機能を提供しています。便利さは間違いありません。しかし、その裏側では「記名記事のクローリングは合法なのか」「記者の情報をAIで解析・活用してよいのか」という、法的整理が追いついていない領域が広がっています。
本記事では、海外AI PRツールの最新動向を紹介しながら、著作権法・個人情報保護法・EU判例をもとに、この領域の「いま」を整理します。
海外PRテックの現在地 — AIが記者を「推薦」する時代
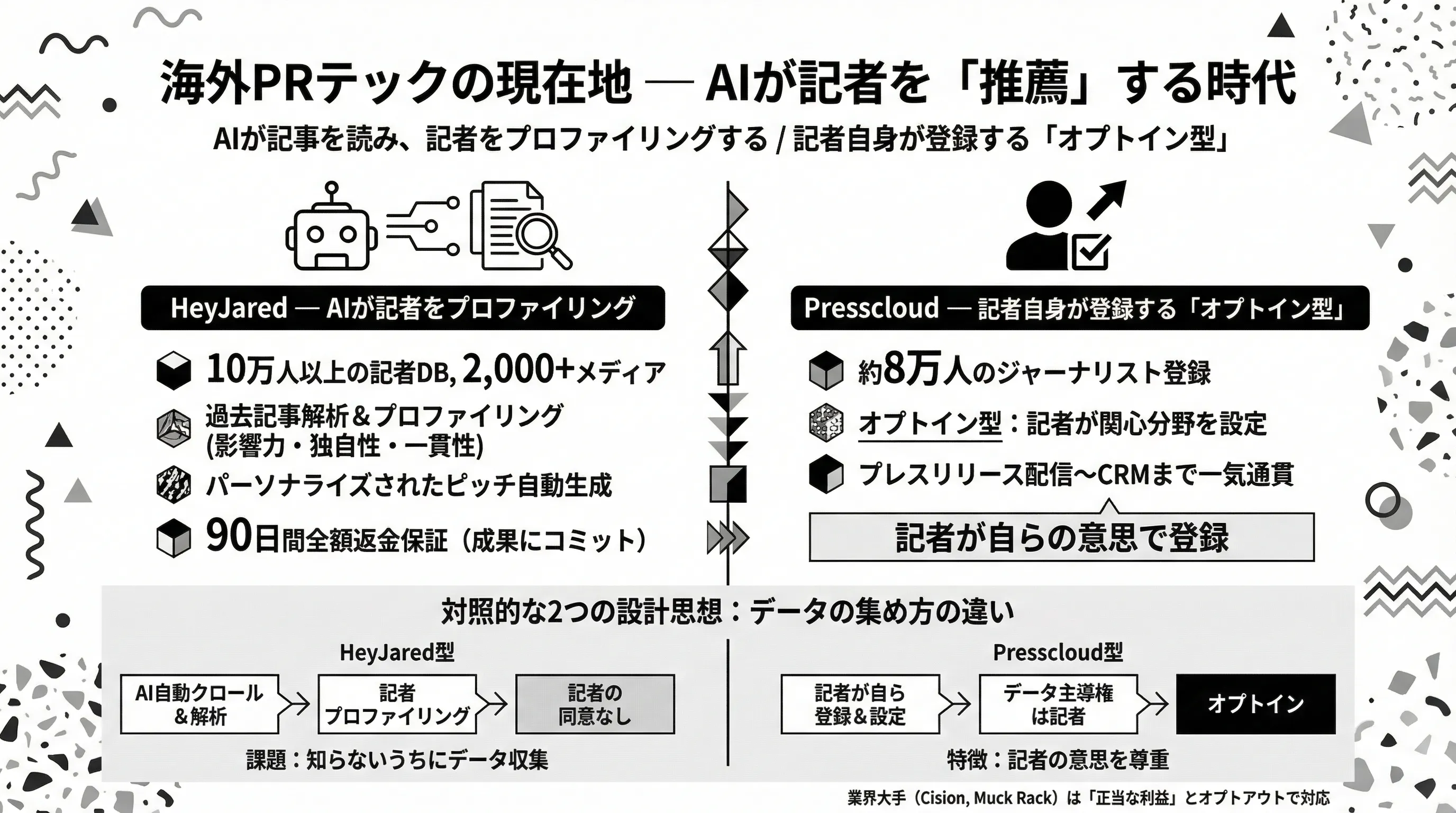
HeyJared — AIが記事を読み、記者をプロファイリングする

HeyJaredは、データサイエンス・AI領域出身のNing Ma氏が創業した米国発のAI PRプラットフォームです。10万人以上の記者データベースと2,000以上のメディアを網羅し、AIがプレスリリースの内容を分析して「この記者に送るべき」と推薦してくれます。
特徴的なのは、記者一人ひとりの過去記事をAIが継続的に解析している点です。担当分野、論調の傾向、最近の関心テーマなどをプロファイリングし、影響力(Influence)・独自性(Originality)・一貫性(Consistency)の3軸でランキング化しています。
さらに、記者ごとにパーソナライズされたピッチ文面をAIが自動生成。従来のPRツールが「記者リストの検索エンジン」だったのに対し、HeyJaredは「AIが戦略を考えてくれるPRアシスタント」に近い存在です。
掲載が取れなければ90日間の全額返金保証を提供するなど、成果にコミットする姿勢も従来のPRツールとは一線を画しています。
Presscloud — 記者自身が登録する「オプトイン型」

一方、PRコンサルタント出身のAaron Mirck氏らが共同創業したオランダ発のPresscloudは、まったく異なるアプローチを取っています。
Presscloudのデータベースには約8万人のジャーナリストが登録されていますが、その特徴は記者自身がプロフィールや関心分野を登録する「オプトイン型」であること。記者が「自分はこういうテーマのプレスリリースを受け取りたい」と設定し、AIがプレスリリースの内容を分析して最適な記者を推薦します。
プレスリリースの自動生成、配信、メディアモニタリング、PR CRMまでを一気通貫で提供しており、欧州を中心に利用が広がっています。
対照的な2つの設計思想
この2つのサービスの違いは、単なる機能差ではありません。データの集め方そのものが根本的に異なります。
- HeyJared型:AIが記事を自動クロールし、記者をプロファイリング。記者の同意は介在しない
- Presscloud型:記者が自らの意思で登録。データの主導権は記者側にある
この設計思想の違いは、後述する法的課題の核心に直結します。HeyJared型のモデルは便利ですが、「記者が知らないうちにデータを収集・活用している」という構造を内包しているからです。
なお、業界大手のCisionやMuck Rackも、大規模な記者データベースをAI解析と組み合わせて提供しています。これらは「正当な利益(Legitimate Interest)」という法的根拠を用い、記者への通知とオプトアウト手段を提供することで運営を正当化しています。
記名記事をAIに読ませるのは合法か?
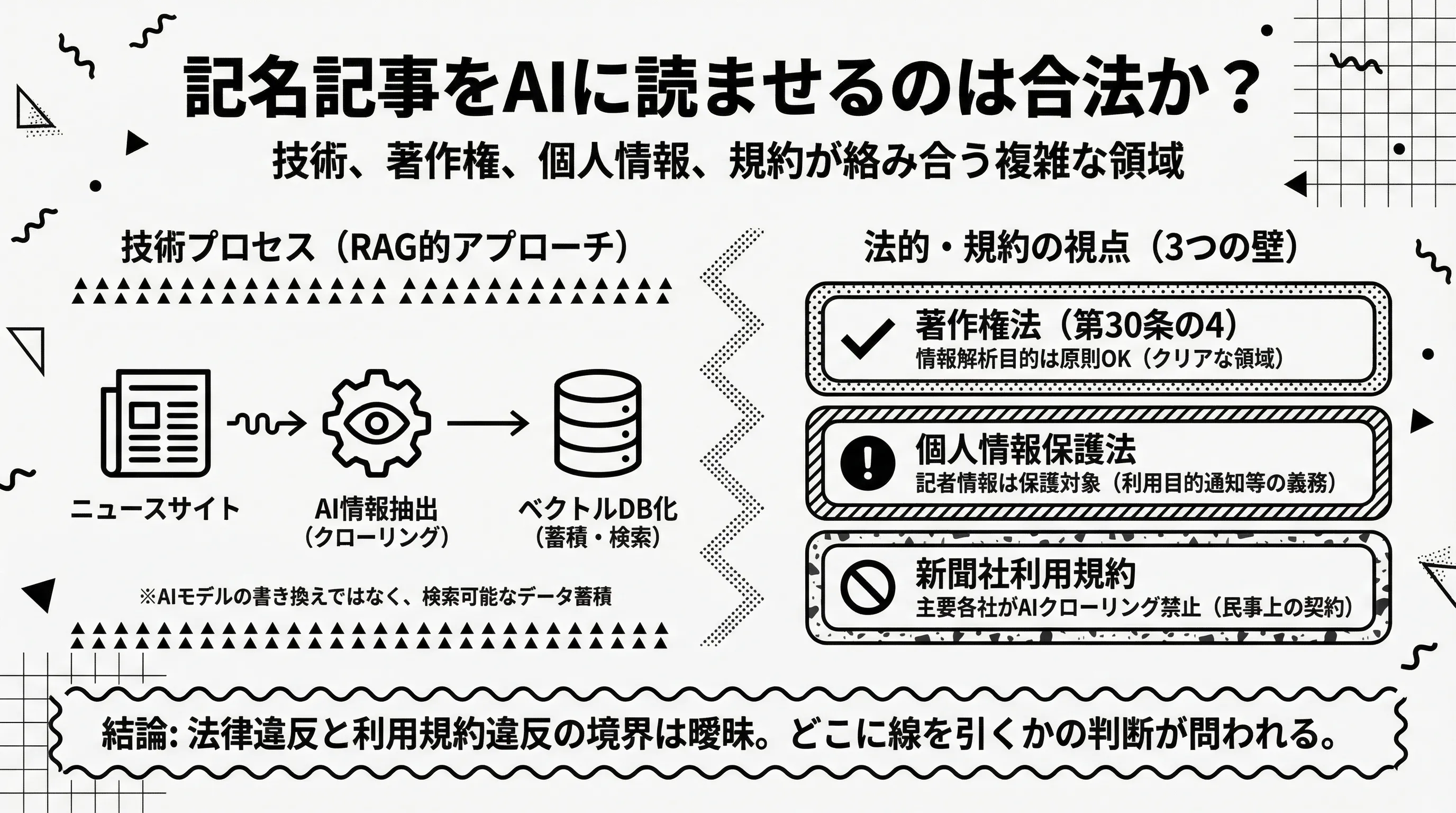
やっていること:記事をクロール → 記者情報をベクトルDB化
HeyJared型のサービスが行っていることを技術的に分解すると、おおむね以下の3ステップです。
- クローリング:ニュースサイトから記名記事を自動収集
- 情報抽出:記事から記者名・所属媒体・担当分野・論調をAIで抽出
- ベクトルDB化:抽出した情報をベクトルデータベースに格納し、プレスリリースとの類似度検索で最適な記者を推薦
ここで使われている技術はLLMのファインチューニング(再学習)ではなく、RAG(Retrieval-Augmented Generation)や埋め込み検索に近いアプローチです。つまり、AIのモデル自体を書き換えているのではなく、記事データを検索可能な形で蓄積し、問い合わせに応じて関連情報を取り出しています。
技術的には珍しくありません。問題は、この一連のプロセスを法律がどう見るかです。
著作権法30条の4 — 情報解析目的の複製は原則OK
まず著作権法の観点から見ると、日本の著作権法第30条の4は「情報解析の用に供する場合」、著作物を著作権者の許諾なく利用できると定めています。
文化庁が2024年3月に公表した「AIと著作権に関する考え方について」でも、AI開発・学習段階での著作物利用は原則として許容される、との見解が示されています。ただし「著作権者の利益を不当に害する場合」はこの限りではないとされています。
記事のテキストをベクトル化して類似度検索に用いる行為は、著作物の「思想又は感情を享受する」目的ではなく情報解析の目的と解釈できるため、著作権法上は比較的クリアな領域です。
しかし、個人情報保護法は別の法律
ここが重要なポイントです。著作権法と個人情報保護法は別の法律であり、著作権法上問題がなくても、個人情報保護法上の義務は別途適用されます。
個人情報保護委員会は公式FAQで以下のように明言しています。
「新聞やインターネットなどで既に公表されている個人情報であっても、利用目的や他の個人情報との照合など取扱いの態様によっては個人の権利利益の侵害につながるおそれがあることから、個人情報保護法では、既に公表されている情報も他の個人情報と区別せず、保護の対象としています」 — 個人情報保護委員会 FAQ Q1-5
つまり、記名記事から抽出した「記者名+所属媒体+担当分野」は個人情報に該当し、その取り扱いには利用目的の通知や第三者提供の制限といった義務がかかります。
「ネット上の公開情報だから自由に使える」は、少なくとも日本の個人情報保護法上は通用しません。
メディア各社の利用規約 — 新聞社が突出して厳しい

興味深いのは、AI目的のクローリングを利用規約で明確に禁止しているのは主に新聞社である点です。
- 日本経済新聞(著作権について):「日経コンテンツを許可なくデータマイニング、テキストマイニングおよびAI開発を目的としたディープラーニングなどの情報処理、情報解析またはAI学習その他の処理のために、蓄積、複製、加工その他の利用を行うことはできません」
- 読売新聞(利用規約 第4条):「クローリング、スクレイピング等の自動化された手段を用いてデータ収集、抽出、加工、解析または蓄積等をする行為」「生成AI等に学習させる行為または生成AI等を開発する行為」を禁止。さらに「本サービスを情報解析のために利用することはできません。利用者がこれを希望する場合には、当社と別途ライセンス契約を締結する必要があります」と明記
- 朝日新聞(利用規約 第10条):「データマイニング、ロボット等によるデータの収集、抽出、解析または蓄積等をする行為、およびAIの開発・学習・利用またはその他の目的のために、情報・データの収集、抽出、解析または蓄積等をする行為」を禁止
- 毎日新聞(利用規約 第9条):「ロボット、スパイダー、スクレーパー等の自動化された手段によって本サービスにアクセスする行為」を禁止
- 中日新聞(利用規約 禁止事項):「本サイトのコンテンツを、中日新聞社の許諾なしにデータマイニング、テキストマイニングおよびAI開発を目的としたディープラーニングなどの情報処理、情報解析のために利用する行為」を禁止
一方、テレビ局や雑誌・出版社のウェブサイトでは、同レベルの明確なAIクローリング禁止条項は確認されていません。 出版社(講談社・集英社等)は生成AIによる著作権侵害に対して共同声明を出していますが、これは主にイラストや漫画の模倣に対する抗議であり、ウェブサイトの利用規約でクローリングを禁止するものとは性質が異なります。
つまり、記名記事のクローリングという文脈では、新聞社サイトが最もハードルが高く、テレビ局や雑誌のウェブ記事は規約上のリスクが相対的に低いという状況です。ただし、Perplexity訴訟などの影響を受け、今後テレビ局やウェブメディアも利用規約を厳格化する可能性は十分にあり、この状況は流動的です。
ただし、ここで押さえておくべき論点があります。利用規約違反は、直ちに「違法」(刑事罰)を意味するわけではありません。 利用規約は民事上の契約であり、違反した場合のリスクは損害賠償請求や差止請求です。
さらに、会員登録が不要で誰でもアクセスできる公開ページの場合、そもそもユーザーと新聞社の間に契約関係が成立しているかどうか自体が議論の余地があります。
法律違反と利用規約違反の境界は曖昧です。だからこそ、各プレイヤーがどこに線を引くかの判断が問われています。
問い合わせ履歴からベクトル検索するのは?
自社に問い合わせてきた記者のデータ活用
視点を変えてみましょう。外部の記事をクローリングするのではなく、自社に取材依頼や問い合わせをしてきた記者の情報をデータベース化し、AIで活用するケースです。
たとえば、以下のような運用です。
- 過去に取材依頼をくれた記者の名前・媒体・取材テーマをDBに蓄積
- 新しいプレスリリースを書いた際に、ベクトル検索で「過去の取材テーマが近い記者」を抽出
- AIがピッチ文面のドラフトを生成
これは本質的に、PR担当者が名刺ファイルをめくって「この記者に送ろう」と判断していた作業をAIで効率化しているだけです。
クローリングとの決定的な違い
この方法とHeyJared型クローリングの決定的な違いは、記者との直接の関係性があるかどうかです。
| クローリング型 | 問い合わせ履歴型 | |
|---|---|---|
| 記者の認知 | 知らないうちにデータ収集 | 記者自身がコンタクトしている |
| 関係性 | なし | 直接のやり取りあり |
| 個人情報保護法上のリスク | 利用目的の通知が困難 | 利用目的の通知が容易 |
Presscloudの「オプトイン型」に近い考え方であり、PR代理店が長年やってきた「人脈のデータベース化」をAIで効率化しているに過ぎません。
個人情報保護法上も、直接のやり取りに基づくデータであり、利用目的を明示していれば大きな問題は生じにくい領域です。
EU判例が示す「公開情報でも自由ではない」
日本ではまだ大きな判例がありませんが、EUではすでに「公開情報のスクレイピング」をめぐって高額な罰金が科されています。これらの判例は、日本でこの領域を考える際の重要な参照点になります。
Clearview AI — 公開写真のスクレイピングで罰金1億ユーロ超
Clearview AIは、SNSやニュースサイト上の公開写真を500億枚以上スクレイピングし、顔認識AIのデータベースを構築した米国企業です。
「写真は公開されていたのだから問題ない」という同社の主張は、EU各国の当局によって完全に退けられました。
- イタリア:2,000万ユーロ
- フランス:2,000万ユーロ
- ギリシャ:2,000万ユーロ
- オランダ:3,050万ユーロ
合計で1億ユーロ(約160億円)を超える罰金が科されています。
主な違反理由は、GDPR第6条(処理の適法性)違反です。Clearview AIは「正当な利益(Legitimate Interest)」を法的根拠として主張しましたが、データ主体(写真の持ち主)の権利と自由を上回る正当性は認められませんでした。
KASPR — LinkedInスクレイピングで罰金24万ユーロ
KASPRはフランスの企業で、ChromeエクステンションでLinkedInのプロフィールから連絡先情報を抽出し、約1.6億件のデータベースを構築していました。
2024年12月、フランスのCNIL(データ保護当局)は同社に24万ユーロの罰金を科しました。特に重要な判断ポイントは以下です。
- LinkedInユーザーが連絡先の公開範囲を「1次つながりのみ」に制限していたにもかかわらず、その設定を無視して連絡先を収集
- 「オンラインでアクセス可能であること」は「自由に再利用可能であること」を意味しない
2026年3月、KASPRはデータベース全体の削除とLinkedInからのデータ収集の完全停止を余儀なくされました。
記者データへの示唆
Clearview AIの顔認識やKASPRの限定公開情報の収集と、記者情報のクローリングとでは性質が異なります。記者の職業情報は業務上公開されているものであり、プライバシーの期待度は相対的に低いと考えられます。
実際、CisionやMuck Rackといった業界大手は「正当な利益」を法的根拠として記者データベースを運営しており、以下の3つの措置を組み合わせることで正当化しています。
- 通知:記者に対してデータベースへの掲載を通知
- オプトアウト:記者がデータの削除を容易に要求できる仕組み
- バランステスト:データ処理による利益とデータ主体の権利への影響を評価
なお、日本の個人情報保護法にはGDPRのような「正当な利益(Legitimate Interest)」に相当する包括的な適法化根拠は存在しません。つまり、CisionやMuck Rackが欧州で用いている正当化ロジックは、日本ではそのまま使えないということです。日本で同様のサービスを展開する場合、利用目的の通知や第三者提供の制限に一層慎重な対応が求められます。
EUの規制も確実に厳格化の方向に進んでいます。フランスのCNILは2025年6月に「AI開発のためのウェブスクレイピング」に関するガイドラインを公表し、robots.txtの遵守やデータ最小化の原則を明確化しました。
参考:Perplexity AI訴訟 — 日本の新聞社が突きつけた「robots.txt無視」の論点
EUの判例だけでなく、日本でもすでにAIによるクローリングをめぐる訴訟が動いています。
2025年8月、読売新聞がAI検索サービスのPerplexity AI(米国)を東京地裁に提訴。約12万本の記事が無断で利用されたとして、約21.7億円の損害賠償を請求しました。続いて同月、朝日新聞と日本経済新聞も共同で提訴し、それぞれ22億円を請求。さらに12月には共同通信・毎日新聞・産経新聞もPerplexityに対して著作権侵害と虚偽表示を指摘しています。
訴訟の主な争点は以下の3つです。
- robots.txtの無視:各新聞社はrobots.txtでクローラーのアクセス拒否を明示していたが、Perplexityはこれを無視して記事を取得
- 有料記事の利用:ペイウォール内の記事までRAG(検索拡張生成)のソースとして使用
- 虚偽情報の生成:新聞社名を引用しながら、元記事と異なる内容を回答として表示
この訴訟は「記事コンテンツのAI利用」に関するものであり、記者の個人情報とは直接の論点ではありません。しかし、「robots.txtを無視したクローリングは許されるか」という論点は、記者データのクローリングにもそのまま当てはまります。
フランスのCNILも2025年6月のガイドラインで「robots.txtで禁止しているサイトからのスクレイピングは不可」と明確化しており、robots.txtの遵守は国際的にも最低限のラインになりつつあります。
朝日と日経、米Perplexityを共同提訴 読売に続き 「記事の無断利用」で計44億円請求 - ITmedia AI+
読売新聞 対 Perplexity訴訟から考える生成AIと著作権の今
AIネイティブ企業の影響とは — 24時間稼働するエージェントの脅威
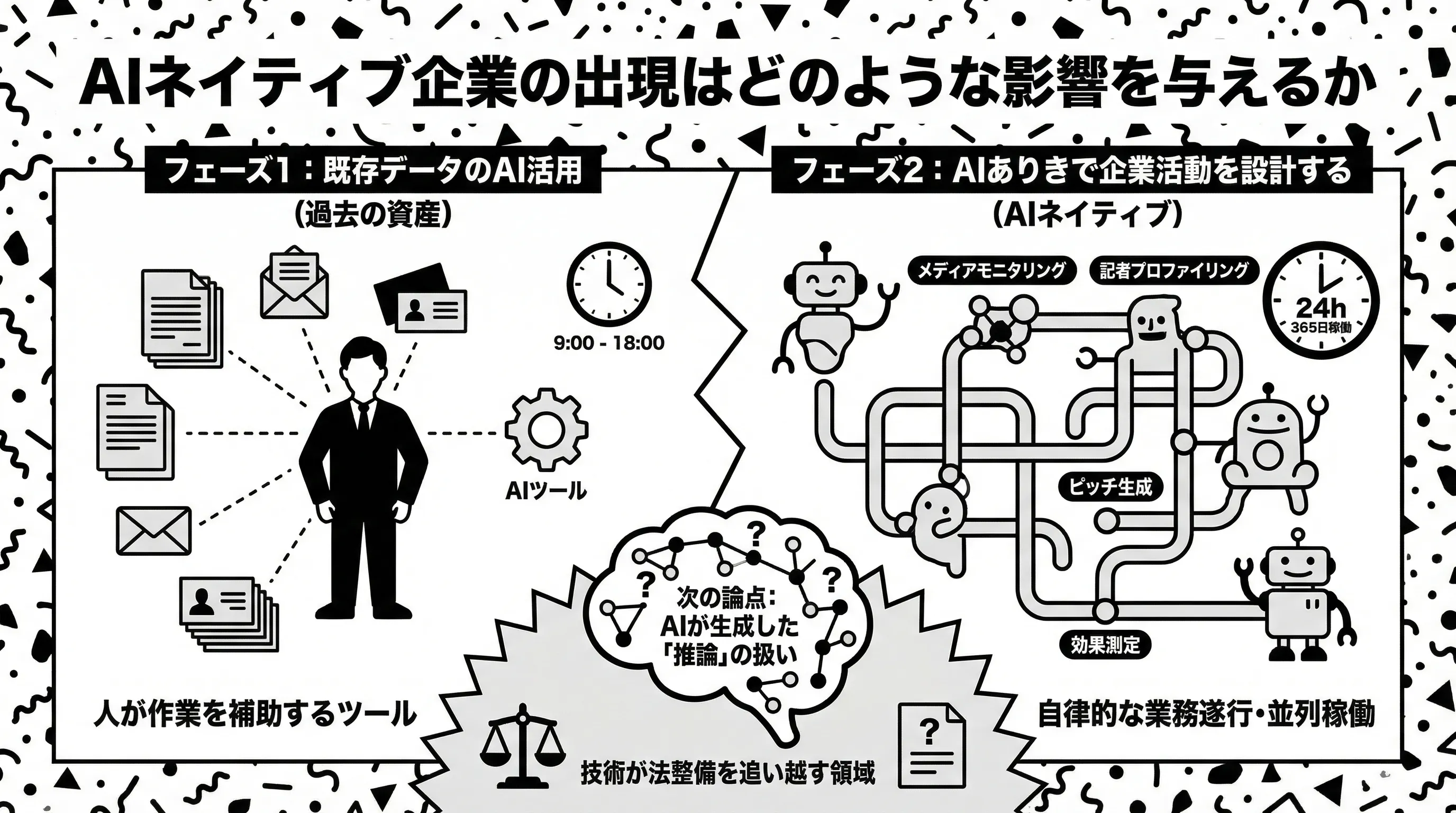
「過去のデータをAIに食わせる」企業と「最初からAI前提で動く」企業
ここまで法的な論点を中心に見てきましたが、もう一つ、実務的に無視できない変化が起きています。
AIの活用には2つのフェーズがあります。
フェーズ1:既存データのAI活用 長年蓄積した名刺データ、メールの履歴、取材対応の記録——こうした「過去の資産」をベクトルDBに入れて検索可能にする。これは多くの企業がいま取り組んでいることです。
フェーズ2:AIありきで企業活動を設計する こちらはまだ少数ですが、本質的に異なります。最初から全ての業務プロセスにAIエージェントを組み込み、企業活動そのものが「AIが処理可能なデータ」として記録される設計です。
Gartnerの予測では、2026年末までに企業アプリケーションの40%がタスク特化型AIエージェントを統合するとされています。DingTalkが発表した「Wukong」は24時間365日稼働するAIネイティブワークプラットフォームであり、物理的なオフィスの制約を超えた自律的な業務遂行を目指しています。
PR領域で何が変わるか
この流れがPR・広報に及ぶとどうなるか。
従来型のPR会社は、人が記事を読み、人が記者との関係を構築し、人がピッチを書いていました。AIは「人の作業を補助するツール」でした。
AIネイティブ企業は違います。
- メディアモニタリングエージェントが24時間記事をクロールし、自社に関連する報道をリアルタイムで検知
- 記者プロファイリングエージェントが記名記事を解析し、記者の関心テーマと論調の変化を追跡
- ピッチ生成エージェントがプレスリリースと記者プロファイルを照合し、個別最適化されたピッチを自動生成
- 効果測定エージェントが掲載結果を分析し、次のアクションを提案
これらが並列で、24時間稼働する。走らせるエージェントの数に応じて成果が上がるという構造です。
人が9時から18時まで働く企業と、10体のエージェントが24時間並列稼働する企業。どちらが多くの記者にリーチし、どちらが速くトレンドを捉えるか。答えは明白です。
次の問い:AIが「読んだ後に考えたこと」は誰のデータか
ここまでの議論は主に「記事データの収集」に焦点を当ててきました。しかし、2026年に入り、もう一つ先の論点が浮上しています。AIが記事を読んだ後に生成する「推論」の扱いです。
従来のRAG(検索拡張生成)は、記事をベクトル化して類似度検索する受動的な仕組みでした。しかし最新の研究では、エージェントが自律的に検索戦略を改善する「エージェンティックRAG」や、過去の検索エピソードから学んで探索精度を高める手法(MR-Searchなど)が登場しています。
ポイントは、AIが単にデータを検索するのではなく、過去の検索履歴を踏まえて「次に何を調べるか」を自律的に判断するようになっている点です。
これをメディアリレーションに応用すると、何が変わるか。
従来のRAG型: 記事テキストをベクトルDBに保存 → 「AI領域に詳しい記者は?」と検索 → 類似度の高い記者を返す
エージェント型: 記事を読む → 過去に蓄積した同じ記者の記事群と照合 → 「この記者は3ヶ月前と論調が変わっている」「最近この分野の取材頻度が上がっている」と推論を生成 → その推論を構造化データとして蓄積 → 次のピッチ判断に反映
ここで重要なのは、エージェントが賢くなるのではなく、参照できるデータが厚みを増すということです。24時間稼働するエージェントが記事を読み続ければ、蓄積される記者プロファイルは日々充実していきます。モデル自体が学習するわけではありませんが、検索・推論の材料が増えることで、結果的にアウトプットの精度は上がります。
そして決定的なのは、元の記事には書かれていない「AIの推論」がデータとして生まれる点です。
たとえば、エージェントが過去50本の記名記事を横断的に分析した結果、「記者Aは環境規制に対して批判的→中立に論調が変化している」というプロファイルを生成したとします。この推論は元記事のどこにも書かれていません。複数の記事を時系列で比較して初めて導き出されたものです。
では、この「AIが生成した推論プロファイル」は法的にどう扱われるのでしょうか。
| データの種類 | 例 | 法的位置づけ |
|---|---|---|
| 元記事のテキスト | 「〇〇記者が△△について報じた」 | 著作物+公開情報 |
| 記者の属性情報 | 名前・所属・担当分野 | 個人情報 |
| AIが生成した推論 | 「この記者は最近論調が変化」「批判的な文脈でのみA社を取り上げる」 | ? |
GDPRには「プロファイリング」に関する規制(第22条)があり、個人に関する自動的な判断を制限しています。しかし日本の個人情報保護法には、AIによるプロファイリングを直接規制する条文はまだありません。
つまり、クローリングの合法性が「現在の論点」だとすれば、AIが生成する推論データの扱いは「次の論点」です。技術が法整備を追い越している典型的な領域であり、ここに早く気づいた企業が先行者利益を取ることになります。
法的グレーゾーンに対してどのように対応すべきか
ここで冒頭の法的議論に戻ります。
記者データのクローリングがグレーだからやらない——これは一つの判断です。しかし、AIネイティブ企業はグレーゾーンの中でリスクを管理しながら先に進みます。
重要なのは、グレーだから止まるのではなく、グレーの中のどこに線を引き、どうリスクを管理するかという判断です。robots.txtは守る、通知とオプトアウトは提供する、しかし公開情報の解析は積極的に行う——こうした線引きの巧拙が、今後の競争力を分けることになるでしょう。
合法と違法のグラデーション
ここまでの議論を踏まえて、記者データ×AI活用の各パターンを整理します。白か黒かではなく、グラデーションで捉えるのが現実的です。
| 行為 | 判定 | 備考 |
|---|---|---|
| 自社問い合わせ履歴をDB化 → ベクトル検索 | ◎ 白 | 直接の関係性に基づく。利用目的を明示していれば問題なし |
| 記者がオプトインで登録したDB(Presscloud型) | ◎ 白 | 記者の同意あり。最もクリーン |
| 記名記事の記者名を手動でリスト化 | ○ ほぼ白 | 従来のPR業務の範囲。規模が小さければ実務上問題にならない |
| 公開記事を自動クロール → 社内AI分析(非公開利用) | △ グレー | 著作権法上はOKだが個人情報保護法上の整理が必要 |
| クロールしたデータをDB化 → SaaSとして外販 | ▲ 濃いグレー | 個人情報の第三者提供に該当しうる。通知・オプトアウトが最低限必要 |
| 新聞社サイトを利用規約無視でクロール | × 規約違反 | 刑事罰ではないが民事リスク。損害賠償・差止請求の対象 |
| プライバシー設定を無視して連絡先を収集 | × 違法 | KASPR判例でGDPR違反が確定済み |
注目すべきは、グレーゾーンの幅が広いことです。「やったら即アウト」という行為は意外と限定的で、多くのケースは「どこまでやるか」「どう管理するか」次第で判定が変わります。
まとめ — 広報×AIの次の一手
技術と法律の現在地
AI技術は、記者情報の収集・解析・推薦を高い精度で自動化できるレベルに到達しています。24時間365日クローリングし、数十万人の記者をベクトルDBに格納し、プレスリリースとの類似度検索で最適な記者を瞬時に推薦する——技術的にはすでに実現されています。
一方、法律はまだこの速度に追いついていません。著作権法と個人情報保護法のねじれ、利用規約違反と違法の境界、EU判例と日本法の温度差。明確な「答え」がない領域が広がっています。
だからこそ、グレーゾーンの中のどこに線を引くかが、各企業の戦略的判断であり、競争力の源泉にもなりえます。
人的メディアリレーション × AIのハイブリッド
現時点で最も実効性が高く、法的リスクも低いアプローチは、人的メディアリレーションとAIのハイブリッドです。
- AIが得意なこと:大量の記事の解析、パターンの発見、類似度検索、ピッチ文面のドラフト生成
- 人が不可欠なこと:記者との信頼関係の構築、文脈を踏まえた判断、倫理的な線引き
AIは「量」と「速度」を担い、人は「信頼」と「判断」を担う。たとえば、AIが最新の記事データをもとにピッチのドラフトと候補記者リストを作成し、PR担当者が記者との関係性や文脈を踏まえた最終判断を行ってからアプローチする——こうした役割分担が、法的にもクリーンで、成果としても最大化できる形だと考えています。
広報のAI活用は、もはや「やるかやらないか」の段階ではなく、「どうやるか」のフェーズに入っています。
この領域のAI活用や、広報PR活動のDXにご関心のある方は、お気軽にお問い合わせください。