第一線の人ほど、意見が割れている

生成AIを業務でどう動かすか。その土台にある「クラウドの最先端モデルを使うのか、手元のローカルモデルで回すのか」という問いで、いま専門家の見解がきれいに割れています。
クラウド側に立つのが勝間和代さんです。半年近くローカルAIを本気で検証した末に、はっきりクラウドへ軸足を移しました。音声入力や大規模言語モデルをローカルで動かそうと、12GBのVRAMを積んだノートパソコンまで購入して試したものの、2026年5月30日のメルマガ「人工知能は結局、ローカルはクラウドにかなわない」で、こう結論づけています。
Groqのような高速チップやGeminiのような大規模モデルに、ローカルはかなわない、と(勝間和代オフィシャルサイト)。勝間さんはこれを自家発電にたとえました。
発電量も安定性も、自家発電は発電所にかなわない。当然といえば当然だ、と。そのうえで基本はクラウドで動かす方針に切り替え、持ち歩くのは高性能パソコンではなくタブレットで十分になった、とまで書いています。ただし、通信が途絶えたときのバックアップとしてローカル環境は残しておくそうです。
これに対してローカル側の最前線にいるのが、AI研究者の清水亮さんです。2025年6月には、自身のチャンネルで「Llama4がMacBookで動く!ローカルLLMの時代が来た」という動画を公開しています(shi3z show)。
128GBのMacBookでも大型モデルが動くこと、トップ層のモデルとの性能差はもう小さくなっていること、しかもローカルなら追加の課金がかからないことを挙げて、ローカルの時代の到来を語っています。
その姿勢は2026年に入っても一貫し、さらに強まっています。3月のnote「多分これから起きること」では、クラウドの向こう側にあるほとんどのAI推論サービスは、ローカルエージェントに置き換えられる可能性がある、と見ています(清水亮 note「多分これから起きること」、2026年3月)。
多分これから起きること|shi3z クラウド推論はローカルエージェントに置き換わりうる。GitHubが動くコードの博物館になる、という読み。自己改良型エージェントsikiの開発記。 note
Claude Codeのおかげで動くプログラムが大量にGitHubへ蓄積された結果、GitHubが巨大な「プログラム博物館」になる。ならば、ゼロからコードを生成するクラウドAIより、その博物館から確実に動く部品を検索してくるローカルエージェントのほうが役に立つ場面が出てくる、という読みです。
この見立ては、5月のドリキンさんとの対談でさらに具体的になります(前篇 ep3125/後篇 ep3126)。
清水さんがローカルに移る理由は、性能の話だけではありません。クラウドのClaudeは一度インターネットの外に出るので、パスワード級の機微情報を渡すことに迂闊さがある。利用が混む時間帯、とくに米国の出勤時間(日本の午前)には目に見えて重くなり、止まることもある。
自作のローカルエージェントに「新しいAI論文を24時間監視して評価させる」ような使い方は、クラウドの従量課金だと費用が読めません。モデルが勝手にバージョンアップして、前のほうが良かった、という事態も起こります。手元で完結するローカルなら、この不確実さから離れられる、という発想です。
賢さの面でも、清水さんは「しきい値を超えた」と見ています。対談では、DeepSeekの最新モデル(V4系)がコンテキスト100万トークンに達し、初めてClaude級の仕事ができるようになった、と評価しました。速度は本質ではなく、5分でも1時間でも、確実に作ってくれればいい、という構えです。
聞き手のドリキンさんも、DGX Sparkを3台つないだローカル環境を本気で構築する実践者で、ローカルの位置づけが「クラウドが落ちたときの保険」から「むしろローカルのほうにメリットがある」へ変わってきた、と語っています。
そしてもう一方の極にいるのが、ソニーで深層学習ツール「Neural Network Console」を手がけ、再生10万回超の入門解説「Deep Learning入門」でも知られる小林由幸さん(YouTubeではFrieve-A名義)です(Deep Learning入門)。
深層学習を一般に広めた研究者が、ローカルAIについては「忘れろ」と言い切ります。その「ローカルAI…?忘れろ。」は、タイトルどおりの徹底したクラウド擁護です(YouTube/講演スライド)。講演とスライドの主張を筆者なりに要約すると、次のようになります。
ローカルAI…?忘れろ。 小型高性能モデルが出るたび注目されるローカルAIだが、合理的に考えればほとんどの人には不要、という理由をまとめた講演資料。 Speaker Deck
- 結論:クラウドの最先端モデルを使え
- 小型モデルが大型最先端モデルに追いついたことはないし、これからもない
- ローカルAIは基本的に高コスト・低性能・低速・非効率
- ローカルはむしろ高くつく(電気代、GPUの遊休、運用負荷)
- 「ローカルはセキュリティ的に安心」は幻想
- 本当に必要になるのはコーナーケースに集中する
ローカルの時代を語る清水さんやドリキンさんと、ローカルを忘れろと言う勝間さんやFrieveさん。第一線の実務家やインフルエンサーでさえ、ここまで真っ二つに分かれます。では、どちらが正しいのか。素直にそう考えたくなりますが、この問いの立て方そのものに落とし穴があります。
議論が噛み合わない本当の理由

論争を並べて気づくのは、みんなが「クラウド vs ローカル」という同じ言葉を使いながら、実は別々のものを比べている点です。
ある人は「最高精度はどちらが上か」を語り、別の人は「自分の仕事に必要な精度を満たせるか」を語っています。さらに別の人は「総コストはどちらが安いか」を、また別の人は「そもそもコードは生成すべきか、検索すべきか」を問題にしています。
論点が違えば結論が違うのは当たり前で、それぞれの主張は、それぞれの土俵では正しいのです。
噛み合わなさの正体は、優劣ではなく、見ている軸のズレにあります。
噛み合わない議論を、2つの命題に分解する
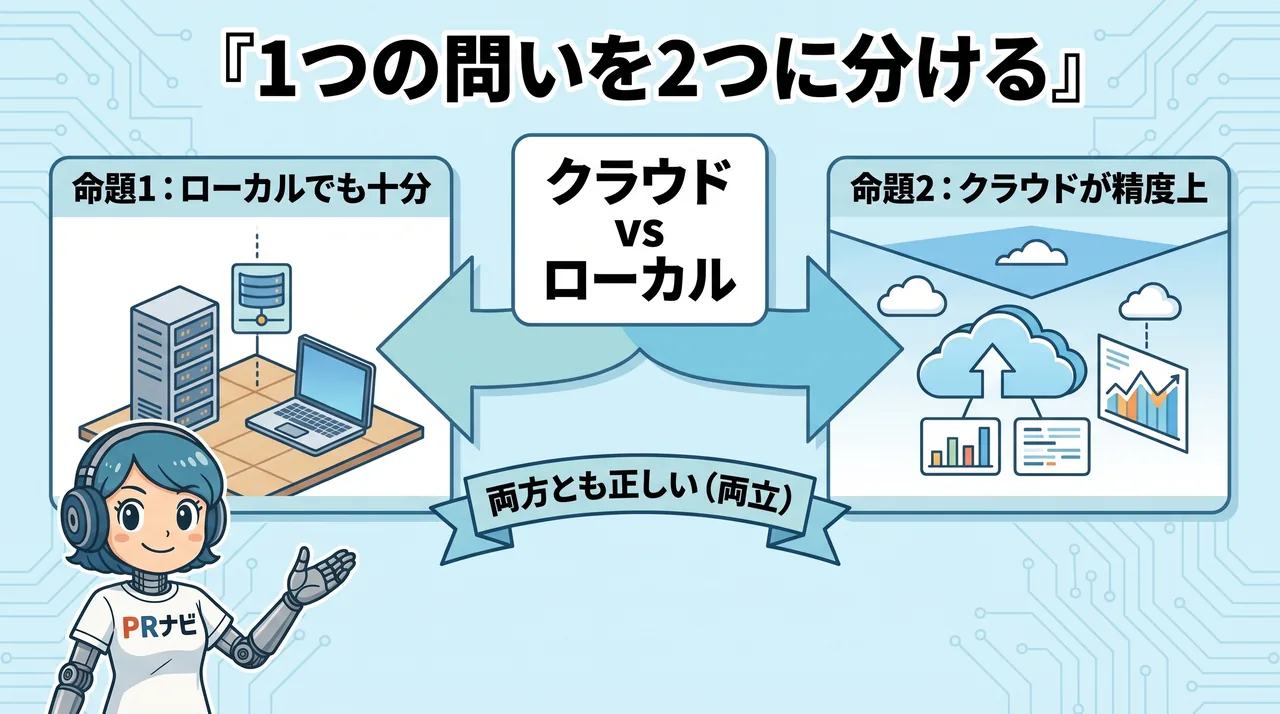
ズレを整理すると、対立の核にある主張は次の2つの命題に集約できます。
命題1:性能が伸び続けるLLMは、ローカルでも十分な業務ができる。
命題2:ローカルよりクラウドのほうが、精度は常に良い。
ここで大事なのは、この2つは矛盾しないという点です。クルマでたとえると分かりやすい。命題2は「最高速度」の話で、スポーツカー(クラウド)は時速300kmまで出る、と言っています。命題1は「制限速度」の話で、日常の道に必要なのは法定速度を満たすことで、軽自動車(ローカル)でもそれは出せる、と言っています。
最高速度の比べ合いと、必要な速度を満たせるかは、別のことを測っています。だから両立します。清水さんの「性能差はもう小さい」は命題1(必要な速度はもう出せる)、勝間さんの「最先端にはかなわない」は命題2(最高速度はクラウド)。どちらも、自分が見ている方については正しい。
勝間さんの自家発電のたとえが、ちょうどこの両面を言い当てています。自家発電が発電所に発電量で勝てないのは命題2そのものです。それでも停電時のバックアップとして自家発電を残す判断は、「最高出力ではなく、その場面に必要な機能」を見る命題1の発想です。クラウドへ転向した勝間さんですら、両方の理屈を同時に持っています。
やっかいなのは、同じ一つの事実認識から、正反対の結論が導けてしまうことです。「LLMは年々良くなっている」という共通認識から、
- 「だからローカルでも十分実用になった。クラウドに毎月課金する必要はない」(命題1ルート)
- 「だからクラウドの最先端はさらに先へ行く。手元で劣化版を使う理由はない」(命題2ルート)
の両方が、同じくらいの説得力で出てきます。だから第一線の人ほど割れます。割れているのは事実認識ではなく、その事実から何を優先して結論を引くか、という視点の置き場所です。
(補足しておくと、性能向上を「指数関数的」と表現する向きもありますが、近年はスケーリング則の鈍化も指摘されています。ここでは「着実に良くなり続けている」程度の意味で押さえておけば十分です。)
ローカル派の最前線:「生成」より「検索」という読み
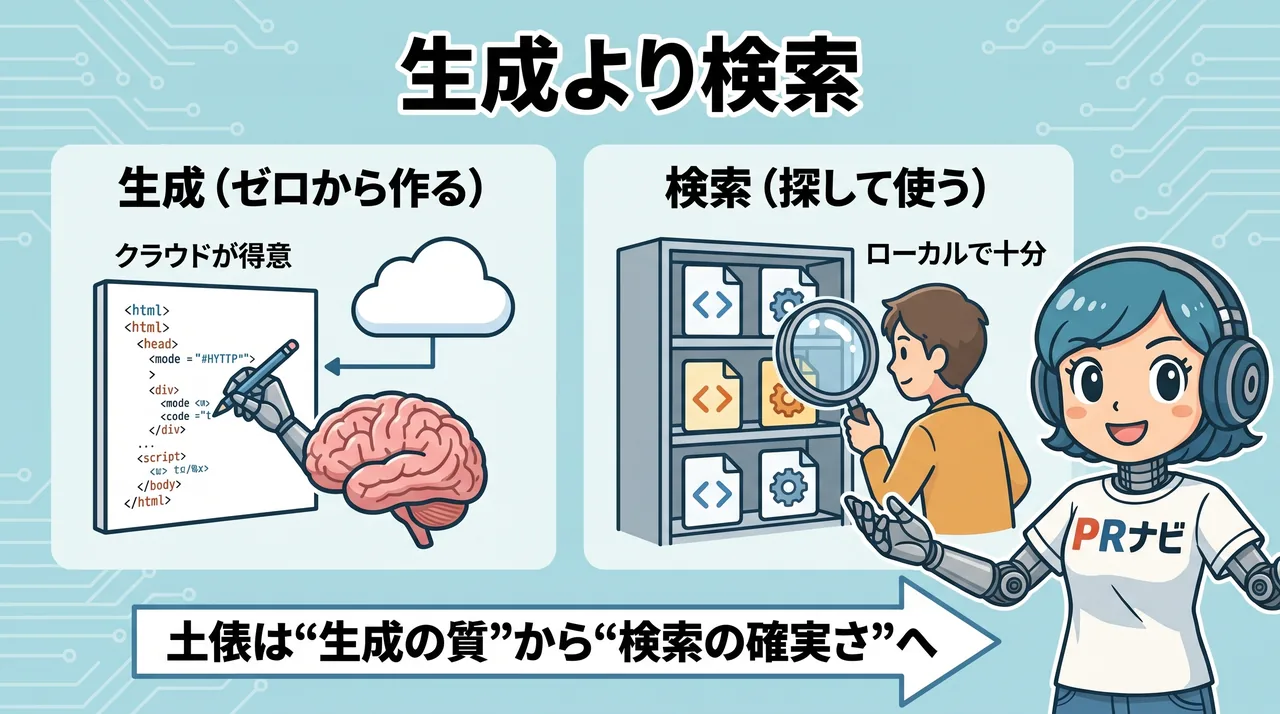
清水さんのGitHub博物館論は、命題1をもう一歩進めます。ここまでの議論は「同じ仕事をクラウドとローカルのどちらでやるか」でした。清水さんはそこで、仕事の中身そのものを問い直します。
コードを書く仕事は、必ずしもゼロから生成する必要はない。すでに動くと分かっているコードが世界中のGitHubに溜まっているなら、それを的確に検索して持ってくるほうが、確実で速い。生成は最先端のクラウドが得意でも、検索と組み合わせるなら手元のローカルエージェントで十分戦える、という発想です。
ここで効いているのは精度の天井ではありません。「その仕事に、最高精度の生成が本当に要るのか」という問いです。要らないなら、勝負の土俵が「生成の質」から「検索と組み立ての確実さ」に移り、ローカルが俄然有利になります。クラウドが強いのはあくまで「ゼロから一番賢く作る」勝負で、すべての仕事がその勝負とは限りません。
「どの視点で話しているか」を仕分けする
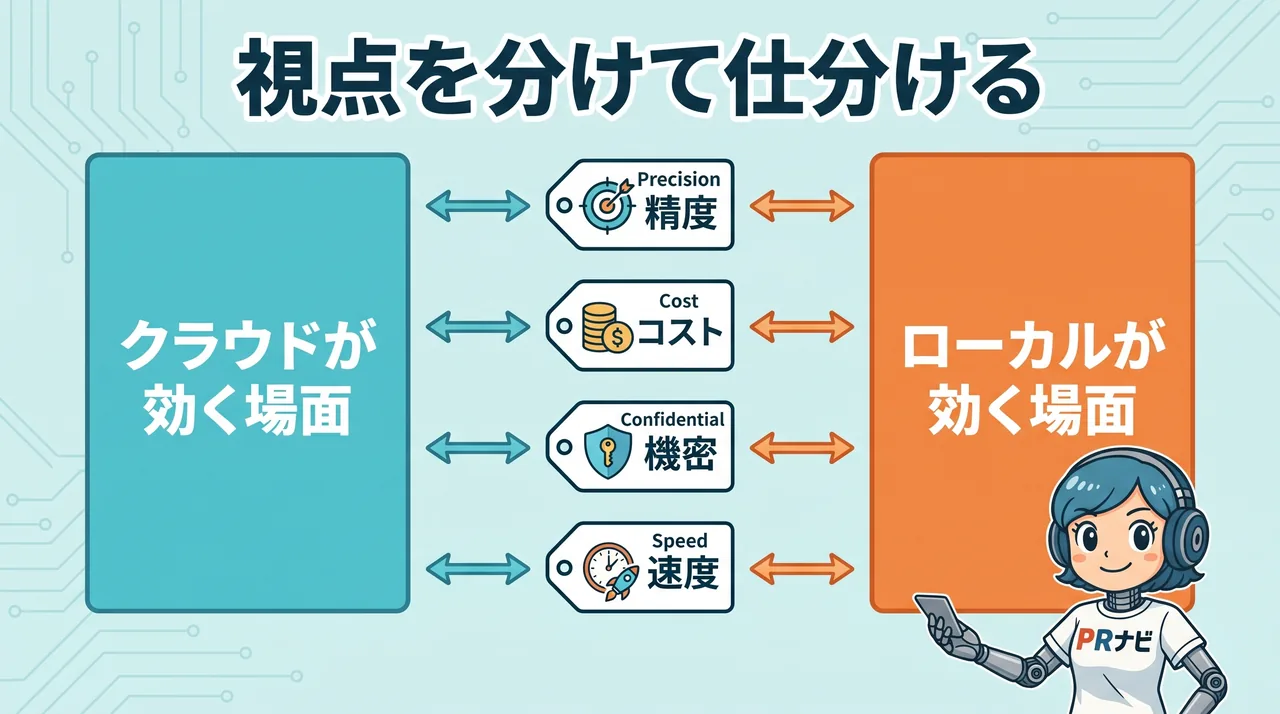
噛み合わせるには、混ざっている視点を分けて、軸ごとに「クラウドが正しい場面」と「ローカルが正しい場面」を仕分けるのが早道です。
| 視点(軸) | クラウド優位を言う立場 | ローカル優位を言う立場 | 仕分けの勘どころ |
|---|---|---|---|
| 絶対性能(最高速度) | 最先端モデルは常にクラウド。最高精度が要る仕事はクラウド一択 | — | その仕事は本当に最高精度が要るのか |
| 必要十分性能(必要な速度) | — | 業務要件を満たせばよく、ローカルで足りる用途は多い(清水「性能差は小さい」) | 要求水準を満たす最小構成はどこか |
| 生成 vs 検索 | ゼロから最も賢く生成できるのはクラウド | 既存の動く資産を検索・再利用するならローカルで十分(清水「GitHub博物館」) | その仕事は新規生成か、既存物の組み合わせか |
| 時間軸 | 最先端は走り続け、差は縮まらない(Frieve) | 数か月前のクラウド相当が手元で動くなら実用十分 | 「今のローカル」と「未来のクラウド」を混ぜて比べない |
| コスト構造 | ローカルは機材・電気・遊休で割高になりがち | 大量・常時利用ではAPI課金が積み上がる。ローカルは課金ゼロ | GPU稼働率が鍵。高稼働で回せるならローカル、散発利用ならクラウド |
| セキュリティ | プロの運用基盤のほうが安全。「ローカルは安心」は幻想 | 規制・契約・オフライン要件で外に出せないデータがある | 「気分の安心」と「契約・法令の要件」を分ける |
| 用途の特殊性 | 大半の用途はクラウドで足りる | オフライン現場、組み込み、特殊規制はローカル必須 | 主流用途かコーナーケースか |
| 運用・技術力 | ローカル運用は枯れた技術で、特別な技術力は不要 | 自社管理できる手離れの良さに価値 | 技術力の有無ではなく、運用を抱える覚悟の問題 |
| タスクの質(推論か量か) | 賢さで差がつく仕事は最先端クラウド | 処理量で差がつく仕事はローカルで回せる | その仕事は賢さで差がつくか、処理量で差がつくか |
この表のポイントは、どの行も「どちらかが嘘をついている」のではなく、見ている軸が違うだけ、という点です。コスト構造の行が象徴的で、ローカルが安いか高いかは、GPUをどれだけ高い稼働率で回せるかでひっくり返ります。24時間エージェントを回し続ける人にはローカルが効き、たまに使うだけの人には遊休した高価なGPUがクラウドより割高になります。同じ「コスト」でも前提が違えば逆の結論になります。
広報・実務の現場ではどう考えるか
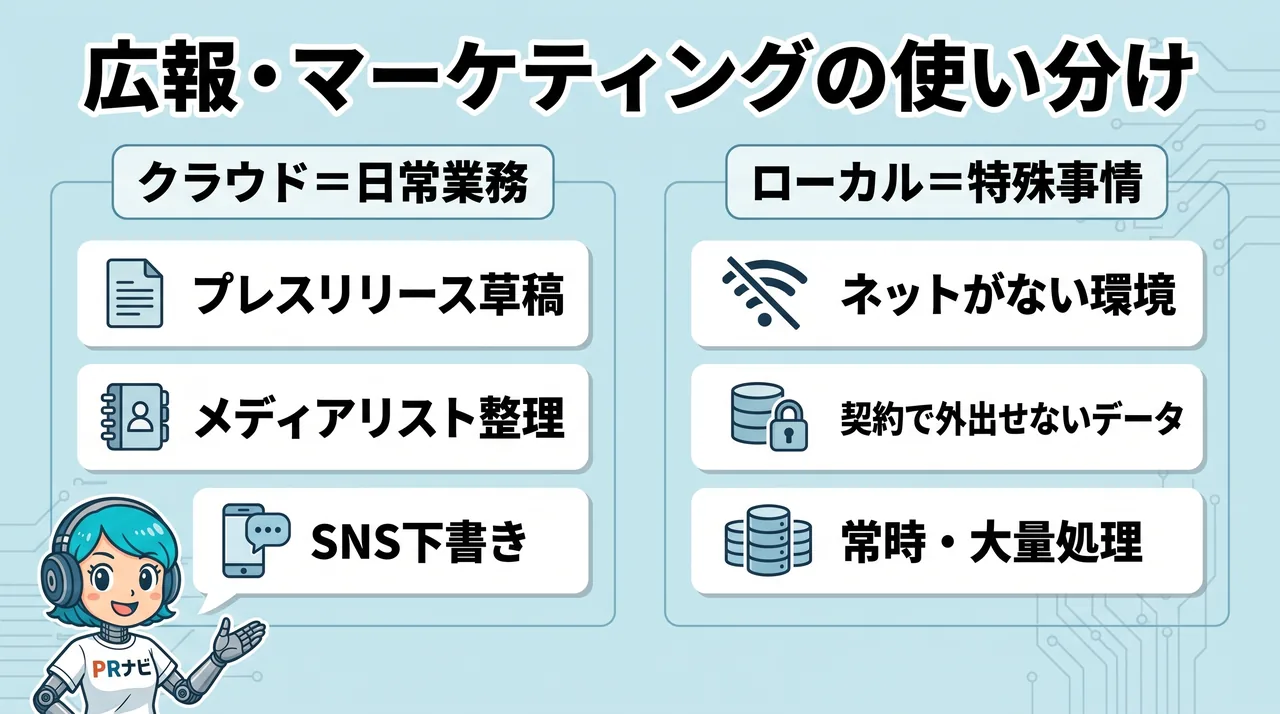
では、一般企業の広報やマーケティングの現場ではどちらを選ぶべきか。視点を仕分けたうえで現実的に言えば、ほとんどの業務はクラウドで足ります。
プレスリリース作成、メディアリスト構築、調査データの分析、SNS投稿作成。こうした仕事の多くは、最高精度よりも必要な水準を満たせば回り、しかも利用は散発的です。散発利用ではローカル機材の遊休コストが重く、クラウドのほうが総額で安くなりやすい。
セキュリティも、契約・法令の要件さえ設計すれば、クラウド側の運用基盤に乗せたほうが現実的です。勝間さんが半年の実験の末に「持ち歩くのはタブレットで十分」と書いたのは、まさにこの判断です。PR戦略の立案のように、ここぞの判断が要る仕事だけは、最高精度のクラウドが効きます。
一方で、ローカルが効く局面もはっきりあります。
- ネット(通信)が届かない場所で動かす(出張先、災害現場、地下や山間部など)
- 規制や顧客との契約で、データを社外に出せないと定められている
- 同じ処理を常時・大量に回し、GPUを高稼働で使い切れる
- 機微情報を自社管理下に置くことが、提案・契約の要件になっている
ここを「なんとなく不安だからローカル」で判断すると、Frieveさんの言う「安心は幻想」に足をすくわれます。逆に「クラウドが最高精度だから全部クラウド」で押し切ると、清水さんが言うような「生成より検索が効く仕事」や、本当にローカルが要る現場で取りこぼします。
ここまでは「今の使い方」を前提にした仕分けでした。AIの使い方そのものを変えると、この前提も動きます。次の結論で、広報の差別化がどこへ向かうのかを詰めます。
なお、ここで言う「必要な水準」をどう見極めるかは、AIに自社をどう認識・引用させるかという広報視点とも地続きです。その考え方は別記事「マシンリレーションズとは|LLMO対策の先にあるAI広報論」でも掘り下げています。
結論:広報AIの差別化は「賢さ」より「処理量」
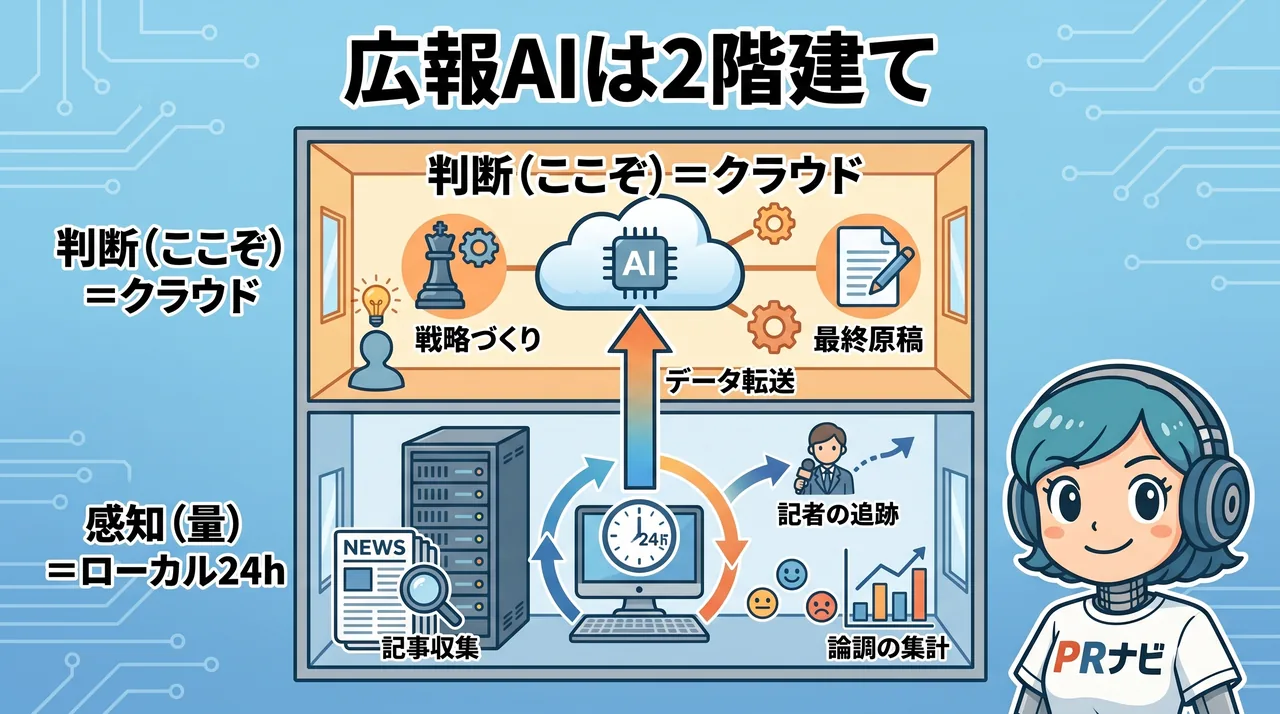
第一線でも答えが割れるのは、各自が違う軸で正しいことを言っているからでした。広報・マーケティングに絞れば、決め手の軸は1本になります。処理量です。
AIに任せたい仕事を並べます。出てきた記事の要点を抜く。どの記者が何を書いているかを追う。媒体ごとの論調を掴む。競合の報じられ方を監視する。どれも最高精度の推論が主役ではありません。賢さより、こなせる量がものを言う。何百本の記事と何十人の記者を、毎日休まず捌けるか。広報AIの最初の差別化は、ここで決まります。
賢さで差がつきにくい仕事なら、最先端クラウドに毎回課金する必然性は薄れます。代わりに効くのが第5章のコストの軸です。たまに使うだけなら遊休するローカルが、24時間動かし続けるなら逆に安くなる。記事の収集も、記者の追跡も、論調の集計も、寝ている間に手元のエージェントが回し続ける。
清水さんが論文を24時間監視させているのが、その実例です(常時・大量で、競合監視データを外に出さず、クラウドの値上げや停止からも独立できる、という条件が揃うほど効きます)。
役割は2階建てで考えると収まります。量をこなす常時稼働の「感知」はローカル、戦略の組み立てや最終原稿という「ここぞの判断」は最先端クラウド。手元で集め、要所でクラウドに利かせる。1社に全部を預けない分散の発想を、広報の現場に落とすとこの形になります。
そう考えると、次に備えるべきは、どのクラウドと契約するかではありません。自分たちで処理を回せる足回り、つまりローカルを扱える力です。量は早く仕組みを作った者から積み上がる。集めた記者データも媒体ごとの論調の癖も、回した分だけ自社に貯まります。
賢いモデルはやがて誰でも安く使えるようになる。残る差は、それを休まず回し切る準備をしているか。問いは「クラウドかローカルか」から「自分で動かし続けられるチームになれるか」へ。広報・マーケこそ、ローカルを持つ準備を始める番です。
追記(2026年6月):頼みの綱が、急に消えることもある
この記事を書いている2026年6月、クラウド側で気になる出来事が続きました。Claudeの最上位級モデル(Fable系)が、米国の輸出規制を理由に公開を止めた、と報じられています。主力のClaude Opus 4.8についても、「以前より応答が軽くなった」「質が落ちた」という声が、ユーザーの間で出ています。
どちらも、特定のクラウドモデル1本に業務を預けることのリスクを、はっきり示しています。規制、仕様変更、値上げ、提供停止。自分ではどうにもできない事情で、頼っていたモデルが急に変わったり、消えたりする。クラウドの最先端は速くて賢い反面、その提供は他社の都合に握られています。
同じ時期、清水さんは別の角度から似た絵を描いています。先のドリキンさんとの対談の後篇(ep3126)では、各社のクラウドAIが収益化のためにAPI課金へ動いており、そうなると料金が高すぎて多くの人はローカルに流れる、と読んでいます。
背景には、AIそのものがコモディティ化しているという見方があります。DeepSeekやQwenのようなオープンソースのモデルがすでに十分賢く、これからもコミュニティの手で進化を続けられるなら、クラウド1社に頼らない選択肢は現実味を増します。
クラウドが揺れる局面と、ローカルが追いついてくる局面が、同じタイミングで重なってきた、という見立てです。
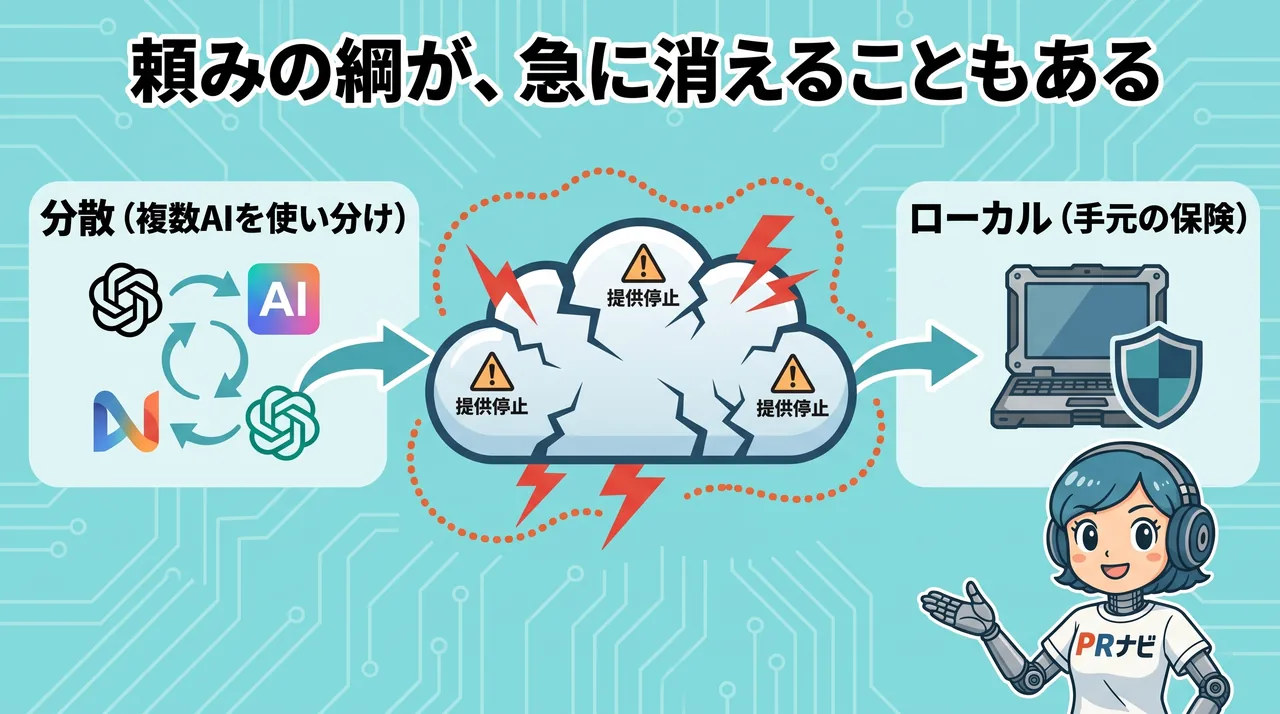
ここで効いてくる備えが、2つあります。
ひとつは分散です。1社のAIに全部を乗せず、複数のAIを使い分けておく。1本が止まっても、別の経路に切り替えられる体制にしておくこと。
分散の発想は、すでに製品にもなり始めています。奇しくも2026年、複数のAIを束ねて使うオーケストレーター「FUGU」が登場しました。Claude・GPT・Geminiの3社を裏で指揮し、1社が止まっても回り続ける仕組みです。

ただし、ここに落とし穴があります。3社への分散をFUGUに任せた瞬間、今度はFUGUそのものに依存します。乗る巨人が、個別のAIからオーケストレーターに移っただけ、とも言えます。便利さと引き換えに、依存の置き場所が一つ上にずれる。だからこそ、最後に自分の足で立てるローカルの備えが効いてきます。
もうひとつがローカルです。最高精度が要らない仕事、機微情報を外に出せない仕事、オフラインや緊急時に動かしたい仕事。こうした場面で、手元で完結する選択肢を持っておく価値は、クラウドが揺れるほど上がります。いざというときに、自分の足で立てる備え、と言い換えてもいいです。
クラウドかローカルか、の二択ではありません。最先端の速さはクラウドで取りにいきつつ、止まったときのために分散とローカルを保険として持っておく。クラウドの最前線が揺れた2026年6月は、その両構えの大切さを、あらためて思い出させてくれました。
クラウドかローカルかは、損得だけの話ではない

ここまで、精度やコスト、処理量という損得で仕分けてきました。第一線がここまで熱くなる背景には、もう一つ別の層があると思います。思想です。
ローカルを推す人の言葉には、しばしば「巨人に全部は預けない」という響きが混じります。クラウドの最先端に乗るのは、賢くて速い巨人の肩に乗ること。ローカルで完結させるのは、その巨人から少し距離を取って、主導権を手元に残すこと。
性能の比較を超えて、どちらの構えを心地よいと感じるか、という価値観がそこにあります。
この感覚には、長い歴史の根っこがあります。そもそもパソコンは、大企業の大型計算機(メインフレーム)に対するカウンターカルチャーの運動として生まれました。書籍『パソコンとヒッピー』(赤田祐一・関根美有、2025年。

雑誌『スペクテイター』48号の特集を書籍化したもの)が描くのは、1970年代アメリカのヒッピーたちが掲げた「コンピュータを個人の手に取り戻す」という思想が、いまのパソコンの出発点にある、という系譜です(『Whole Earth Catalog』や「人民のためのコンピュータ」の流れ)。
Appleの「Think Different」や、巨大なビッグ・ブラザーをハンマーで砕く1984年のCMも、この延長線上にあります。
皮肉なのは、反権力の象徴だったAppleが、いまや最大の巨人の一つになったこと。それでも、Macで手元のローカルAIを回したがる人にこの気質が色濃く見えるのは、偶然ではない気がします。
念のため、これは一面の見方です。ローカルを選ぶ理由が純粋に損得(コストや機密)の人も多く、クラウドを推す側にも第一線の研究者がいます。技術では決着がつきそうな場面で議論が割れ続ける背景に「巨人に乗るか、巨人から離れるか」という構えの違いを置くと、論争の温度がよく見えてきます。
広報・マーケティングにとっても、これは他人事ではありません。どのAIに依存し、どこを手元に残すか。効率の計算であると同時に、自社の主導権をどこに置くかという経営の構え方の問題です。結論で「ローカルを扱える力を持て」と書いたのは、損得であると同時に、この自律の構えの話でもあります。
参考リンク
- 勝間和代「人工知能は結局、ローカルはクラウドにかなわない」(メルマガ/2026-05-30、クラウド派の結論)
- 勝間和代「ノートパソコンにローカルのLLMを入れるのに四苦八苦中」(2026-03-19、実験途中の記録)
- 清水亮(shi3z show)「ハッカー魂 Llama4がMacBookで動く!ローカルLLMの時代が来た」(2025-06-19、ローカル派)
- 清水亮 note「多分これから起きること」(2026年3月、クラウド推論のローカル置換/GitHub博物館論)
- 散財小説ドリキン「【前篇】ローカルLLM最強環境とオープンソース化が変える未来【AIドリフト】ep3125」(ゲスト:清水亮、2026-05)
- 同 後篇 ep3126
- Frieve-A(本名・小林由幸さん)講演「【AI】ローカルAI…?忘れろ。」
- Frieve(小林由幸)講演スライド(speakerdeck、2026-03-29)
- 小林由幸(Neural Network Console)「Deep Learning入門:Deep Learningとは?」(2018、ソニーの深層学習解説/小林さんの肩書き裏付け)
- 赤田祐一・関根美有『パソコンとヒッピー』(2025、文庫。Spectator48号の書籍化/パソコンの対抗文化的な出自)
- Apple「Think Different(Here's to the Crazy Ones)」(1997、ローンチ広告)
- Sakana AI「Sakana Fugu」(複数AIを束ねるオーケストレーター/2026)